
Abstract
Artificial intelligence can assist providers in a variety of patient care and intelligent health systems. Artificial intelligence techniques ranging from machine learning to deep learning are prevalent in healthcare for disease diagnosis, drug discovery, and patient risk identification. Numerous medical data sources are required to perfectly diagnose diseases using artificial intelligence techniques, such as ultrasound, magnetic resonance imaging, mammography, genomics, computed tomography scan, etc. Furthermore, artificial intelligence primarily enhanced the infirmary experience and sped up preparing patients to continue their rehabilitation at home. This article covers the comprehensive survey based on artificial intelligence techniques to diagnose numerous diseases such as Alzheimer, cancer, diabetes, chronic heart disease, tuberculosis, stroke and cerebrovascular, hypertension, skin, and liver disease. We conducted an extensive survey including the used medical imaging dataset and their feature extraction and classification process for predictions. Preferred reporting items for systematic reviews and Meta-Analysis guidelines are used to select the articles published up to October 2020 on the Web of Science, Scopus, Google Scholar, PubMed, Excerpta Medical Database, and Psychology Information for early prediction of distinct kinds of diseases using artificial intelligence-based techniques. Based on the study of different articles on disease diagnosis, the results are also compared using various quality parameters such as prediction rate, accuracy, sensitivity, specificity, the area under curve precision, recall, and F1-score.
Similar content being viewed by others


1 Introduction
Healthcare is shaping up in front of our eyes with advances in digital healthcare technologies such as artificial intelligence (AI), 3D printing, robotics, nanotechnology, etc. Digitized healthcare presents numerous opportunities for reducing human errors, improving clinical outcomes, tracking data over time, etc. AI methods from machine learning to deep learning assume a crucial function in numerous well-being-related domains, including improving new clinical systems, patient information and records, and treating various illnesses (Usyal et al. 2020; Zebene et al. 2019). The AI techniques are also most efficient in identifying the diagnosis of different types of diseases. The presence of computerized reasoning (AI) as a method for improved medical services offers unprecedented occasions to recuperate patient and clinical group results, decrease costs, etc. The models used are not limited to computerization, such as providing patients, “family” (Musleh et al. 2019; Dabowsa et al. 2017), and medical service experts for data creation and suggestions as well as disclosure of data for shared evaluation building. AI can also help to recognize the precise demographics or environmental areas where the frequency of illness or high-risk behaviors exists. Researchers have effectively used deep learning classifications in diagnostic approaches to computing links between the built environment and obesity frequency (Bhatt et al. 2019; Plawiak et al. 2018).
AI algorithms must be trained on population-representative information to accomplish presentation levels essential for adaptable “accomplishment”. Trends, such as the charge for putting away and directing realities, information collection through electronic well-being records (Minaee et al. 2020; Kumar 2020), and exponential client state of information, have made a data-rich medical care biological system. This enlargement in health care data struggles with the lack of well-organized mechanisms for integrating and reconciling these data ahead of their current silos. However, numerous frameworks and principles facilitate summation and accomplish adequate data quantity for AI (Vasal et al. 2020). The challenges in the operational dynamism of AI technologies in healthcare systems are immeasurable despite the information that this is one of the most vital expansion areas in biomedical research (Kumar et al. 2020). The AI commune must build an integrated best practice method for execution and safeguarding by incorporating active best practices of principled inclusivity, software growth, implementation science, and individual–workstation interaction. At the same time, AI applications have an enormous ability to work on patient outcomes. Simultaneously, they could make significant hazards regarding inappropriate patient risk assessment, diagnostic inaccuracy, healing recommendations, privacy breaches, and other harms (Gouda et al. 2020; Khan and Member 2020).
Researchers have used various AI-based techniques such as machine and deep learning models to detect the diseases such as skin, liver, heart, alzhemier, etc. that need to be diagnosed early. Hence, in related work, the techniques like Boltzmann machine, K nearest neighbour (kNN), support vector machine (SVM), decision tree, logistic regression, fuzzy logic, and artificial neural network to diagnose the diseases are presented along with their accuracies. For example, a research study by Dabowsa et al. (2017) used a backpropagation neural network in diagnosing skin disease to achieve the highest level of accuracy. The authors used real-world data collected from the dermatology department. Ansari et al. (2011) used a recurrent neural network (RNN) to diagnose liver disease hepatitis virus and achieved 97.59%, while a feed-forward neural network achieved 100%. Owasis et al. (2019) got 97.057 area under the curve by using residual neural network and long short-term memory to diagnose gastrointestinal disease. Khan and Member (2020) introduced a computerized arrangement framework to recover the data designs. They proposed a five-phase machine learning pipeline that further arranged each stage in various sub levels. They built a classifier framework alongside information change and highlighted choice procedures inserted inside a test and information investigation plan. Skaane et al. (2013) enquired the property of digital breast tomosynthesis on period and detected cancer in residents based screening. They did a self-determining dual analysis examination by engaging ladies of 50–69 years and comparing full-field digitized mammography plus data building tool with full-field digital mammography. Accumulation of the data building tool resulted in a non-significant enhancement in sensitivity by 76.2% and a significant increase by 96.4%. Tigga et al. (2020) aimed to assess the diabetic risk among the patients based on their lifestyle, daily routines, health problems, etc. They experimented on 952 collected via an offline and online questionnaire. The same was applied to the Pima Indian Diabetes database. The random forest classifier stood out to be the best algorithm. Alfian et al. (2018) presented a personalized healthcare monitoring system using Bluetooth-based sensors and real-time data processing. It gathers the user’s vital signs data such as blood pressure, heart rate, weight, and blood glucose from sensor nodes to a smartphone. Katherine et al. (2019) gave an overview of the types of data encountered during the setting of chronic disease. Using various machine learning algorithms, they explained the extreme value theory to better quantify severity and risk in chronic disease. Gonsalves et al. (2019) aimed to predict coronary heart disease using historical medical data via machine learning technology. The presented work supported three supervised learning techniques named Naïve Bayes, Support vector machine, and Decision tree to find the correlations in coronary heart disease, which would help improve the prediction rate. The authors worked on the South African Heart Disease dataset of 462 instances and machine learning techniques using 10-fold cross-validation. Momin et al. (2019) proposed a secure internet of things-based healthcare system utilizing a body sensor network called body sensor network care to accomplish the requirements efficiently. The sensors used analogue to digital converter, Microcontroller, cloud database, network, etc. A study by Ijaz et al. (2018) has used IoT for a healthcare monitoring system for diabetes and hypertension patients at home and used personal healthcare devices that perceive and estimate a persons’ biomedical signals. The system can notify health personnel in real-time when patients experience emergencies. Shabut et al. (2018) introduced an examination to improve a smart, versatile, empowered master to play out a programmed discovery of tuberculosis. They applied administered AI method to achieve parallel grouping from eighteenth lower request shading minutes. Their test indicated a precision of 98.4%, particularly for the tuberculosis antigen explicit counteracting agent identification on the portable stage. Tran et al. (2019) provided the global trends and developments of artificial intelligence applications related to stroke and heart diseases to identify the research gaps and suggest future research directions. Matusoka et al. (2020) stated that the mindfulness, treatment, and control of hypertension are the most significant in overcoming stroke and cardiovascular infection. Rathod et al. (2018) proposed an automated image-based retrieval system for skin disease using machine learning classification. Srinivasu et al. (2021a, b) proposed an effective model that can help doctors diagnose skin disease efficiently. The system combined neural networks with MobileNet V2 and Long Short Term Memory (LSTM) with an accuracy rate of 85%, exceeding other state-of-the-art deep models of deep learning neural networks. This system utilized the technique to analyse, process, and relegate the image data predicted based on various features. As a result, it gave more accuracy and generated faster results as compared to the traditional methods. Uehara et al. (2018) worked at the Japanese extremely chubby patients utilizing artificial brainpower with rule extraction procedure. They had 79 Non-alcoholic steatohepatitis, and 23 non- Non-alcoholic steatohepatitis patients analyse d to make the desired model. They accomplished the prescient exactness by 79.2%. Ijaz et al. (2020) propose a cervical cancer prediction model for early prediction of cervical cancer using risk factors as inputs. The authors utilize several machine learning approaches and outlier detection for different pre-processing tasks. Srinivasu et al. (2021a, b) used an AW-HARIS algorithm to perform automated segmentation of CT scan images to identify abnormalities in the human liver. It is observed that the proposed approach has outperformed in the majority of the cases with an accuracy of 78%.
To fully understand how AI assists in the diagnosis and prediction of a disease, it is essential to understand the use and applicability of diverse techniques such as SVM, KNN, Naïve Bayes, Decision Tree, Ada Boost, Random Forest, K-Mean clustering, RNN, Convolutional neural networks (CNN), Deep-CNN, Generative Adversarial Networks (GAN), and Long short-term memory (LSTM) and many others for various disease detection system (Owasis et al. 2019; Nithya et al. 2020). We conducted an extensive survey based on the machine and deep learning models for disease diagnosis. The study covers the review of various diseases and their diagnostic methods using AI techniques. This contribution explains by addressing the four research questions: RQ1. What is the state-of-the-art research for AI in disease diagnosis? RQ2. What are the various types of diseases wherein AI is applied? RQ3. What are the emergent limitations and challenges that the literature advances for this research area? RQ4.What are the future avenues in healthcare that might benefit from the application of AI? The rest of the work is organized into various sections. Initially, a brief description of AI in healthcare and disease diagnosis using multiple machines and deep learning techniques is given in Sect. 1. Then, it is named an introduction that includes Fig. 1 to describe all the papers taken from different organized sources for various diseases in the contribution sub-section. Materials and Methods is named as Sect. 2, which includes the quality assessment and the investigation part regarding AI techniques and applications. Section 3 covers symptoms of diseases and challenges to diagnostics, a framework for AI in disease detection modelling, and various AI applications in healthcare. Section 4 includes the reported work of multiple diseases and the comparative analysis of different techniques with the used dataset, applied machine and deep learning methods with computed outcomes in terms of various parameters such as accuracy, sensitivity, specificity, the area under the curve, and F-score. In Sect. 5, the discussion part is covered that answers the investigation part mentioned in Sect. 2. Finally, in Sect. 6, the work that helps researchers chooses the best approach for diagnosing the diseases is concluded along with the future scope.

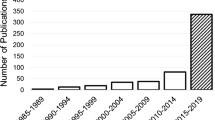
Distribution of published papers for diseases diagnosis using artificial intelligence techniques
1.1 Contribution
Diseases usually are quantified by signs and symptoms. A sign is identified as an objective appearance of a disease that doctors can specify, whereas a symptom is a particular indication of the patient’s illness (Plawiak et al. 2018). Thus, every disease has various signs and symptoms, such as fever, which is found in countless conditions.
As shown in Fig. 1, the number of papers reviewed under preferred reporting items for systematic reviews and Meta-Analysis (PRISMA) guidelines for different types of diseases using AI from the year 2009 to the year 2020. The present work emphasizes various diseases and their diagnostics measures using machine and deep learning classifications. To the best of our knowledge, most of the past work focused on disease diagnostics for one or two disease prediction systems. Hence, the present study explores ten different disease symptoms and their detection using AI techniques. Furthermore, this paper is unique, as it contains an elaborate discussion about various disease diagnoses and predictions based upon the extensive survey conducted for detection methods.
2 Materials and methods
We have directed this review according to the preferred reporting items for systematic reviews and Meta-Analysis guidelines. The survey offers the readers wide-ranging knowledge of the literature on AI (decision tree, which breaks down the dataset into smaller subsets and to build it, two types of entropy using frequencies are calculated in which X, S is a discrete random variable which occurs with probability p(i),…. p(c) and logarithm with base 2 gives the unit of bits or Shannons where entropy using the frequency table of one attribute is given as (Sabottke and Spieler 2020)
and entropy using the frequency table of two attributes is given as
K-nearest neighbour algorithm is a supervised machine learning technique that is used to solve classification issues as well as to calculate the distance between the test data and the input to give the prediction by using Euclidean distance formula in which p, q are the two points in Euclidean n-space, and qi and pi are the Euclidean vectors starting from the origin of the space (Zaar et al. 2020).
Whereas regression is used to determine the relationship between independent and dependent variables. The equation Y represents it is equal to an X plus b, where Y is the dependent variable, an is the slope of the regression equation, x is the independent variable, and b is constant (Kolkur et al. 2018)
where Y is the dependent variable, X is the independent variable; a is the intercept, b is the slope and is the residual error, Naïve Bayes which provides a way of calculating the posterior probability, P (c | x) from P(c), P(x) and P(x | c). Naïve Bayes classifier assumes that the effect of the value of an attribute (x) on a given class (c) is independent of the values of other predictors (Spann et al. 2020)
P(c | x) is the posterior probability of class given attribute, P(x | c) is the likelihood which is the probability of the attribute given class, P(x) is the prior probability of attribute, P(c) is the prior probability of a class, k-means ( Fujita et al. 2020) which is used to define k centers, one for each cluster and these centres should be placed far away from each other. This algorithm also aims at minimizing an objective function which is known as squared error function, given by :
||xi-vj|| is the Euclidean distance between xi-vj, Ci is the number of data points in ith cluster, C is the number of cluster center’s, convolution neural network which is a type of feed-forward artificial neural network in which the connectivity pattern between its neurons is inspired by the organization of the animal visual cortex. Convolution is the first step in the process that convolution neural network undergoes (Zhang et al. 2019)
where (f*g)(t) = functions that are being convoluted, t = real number variable of functions f and g, g(\(\tau\)) = convolution of time function, \({\tau }^{\prime}\) = first derivative of tau function, a recurrent neural network which is used for handling sequential data and its formula in which h(t) is a function f of the previously hidden state h(t − 1) and the current input x(t). The theta are the parameters of the function f is (Yang et al. 2020)
Boltzmann machine, which optimizes the weights, a quantity related to the particular problem. Its main objective is to maximize the Consensus function (CF), which is given by the following formula (Zhou et al. 2019)
where Ui and Uj are the set of units, wij is the fixed weight, gradient descent which is an iterative process and is formulated by (Chang et al. 2018)
where \(\theta\)1 is the next position, \(\theta\)0 is the current position, \(\alpha\) is the small step, \(\nabla J\left(\theta \right)\) is the direction of fastest increase) in healthcare (Zhang et al. 2017). The extensive survey also promotes expounding prevailing knowledge gaps and subsequent identification of paths for future research (Lin et al. 2019). The current study reformed the structure, which produced wide-ranging article valuation standards from earlier published articles. Articles incorporated in our research are selected using keywords like “Artificial Intelligence”, “Disease Detection”, “Disease diagnosis using machine learning”, “Disease diagnosis using deep learning”, “Artificial Intelligence in Healthcare”, and combinations of these keywords. In addition, research articles associated with the applications of AI-based techniques in predicting diseases and diagnosing them are incorporated for review. Table 1 lists the publications that are included or omitted based on a variety of criteria such as time, studies to define how old papers/articles can be accessed, the problem on which the article is based, comparative analysis of the work, methods to represent the techniques used, and research design to analyse the results that are obtained. These characteristics assisted us in carrying out the research study very quickly, without wasting time on irrelevant or unnecessary searches and investigations. The standards for inclusion and exclusion are developed by the requirements of the problem of an article.
2.1 Quality assessment
Research articles included in this review are identified using several quality evaluation constraints. The significance of the study is assessed based on inclusion and exclusion standards. All research articles included for review encompass machine or deep learning-based prediction models for automatically detecting and diagnosing diseases. Each research work incorporated in this study carried empirical research and had experimental outcomes. The description of these research articles is stated in a separate subsection entitled literature survey.
The comprehensive selection of research papers is carried out in four phases: (1) identifying where records are identified through various databases. At this phase, we must do the searches we’ve planned through the abstract and citation databases we’ve chosen. Take note of how many results the searches returned. We can also include data found in other places, such as Google Scholar or the reference lists of related papers. Then, in one citation management application, aggregate all of the records retrieved from the searches. Keep in mind that each database has its own set of rules for searching for terms of interest and combining keywords for a more efficient search. As a result, our search technique may vary significantly depending on the database, (2) screening the selection process is done transparently by reporting on decisions made at various stages of the systematic review. One of the investigators reviews the title and abstract of each record to see if the publication provides information that might be useful or relevant to the systematic review. In certain situations, the title and abstract screening is done by two investigators. They don’t split the job amongst themselves! Each investigator screens every title and abstract, and then their judgments are compared. If one of them decides to leave out an item that the other thinks should be included, they may go over the entire text together and come to a common conclusion. They can also enlist the help of a third party (usually the project manager or main investigator) to decide whether or not the study should be included. Make sure that the most acceptable justification for excluding an item is chosen. (3) Eligibility we study the complete contents of the articles that cleared the title and abstract screening to see whether they may assist in answering our research topic. Two investigators do this full-text screening. Each one examines the entire content of each article before deciding whether or not to include it. We must note the number of articles we remove and the number of articles under each cause for exclusion in the full-text screening, just as we did in the title/abstract screening. Hence, in this stage, full-text articles are assessed and then finally are included in qualitative analysis in (4) included phase by utilizing the Preferred reporting items for systematic reviews and meta-analysis (PRISMA) flowchart as depicted in Fig. 2. In this stage, we’ll know how many papers will be included in our systematic review after removing irrelevant studies from the full-text screen. We assess how many of these studies may be included in a quantitative synthesis, commonly known as “meta-analysis,“ in the fourth and final screening stage.

PRISMA flow chart
To address the RQ1, RQ2, RQ3, and RQ4, the current survey examined the number of articles on different disease diagnoses using AI techniques from various data sources, including Psychological Information, Excerpta Medica Database, Google Scholar, PubMed, Scopus, and Web of Science. The above sources are popular sources of information for articles on AI in health informatics in previous studies. As previously explained, articles are chosen based on specified inclusion and exclusion criteria (Zhang et al. 2017). These were derived from (Behera et al. 2019), where the authors established and accepted the variations. To better understand the state of research on AI in disease detection, peer-reviewed papers are cited. The current review suggests that AI and healthcare have developed a present synergy.
2.2 Investigation
Investigation 1: Why do we need AI?
Investigation 2: What is the impact of AI on medical diagnosis and treatment?
Investigation 3: Why is AI important, and how is it used to analyse these diseases?
Investigation 4: Which AI-based algorithm is used in disease diagnosis?
Investigation 5: What are the challenges faced by the researchers while using AI models in several disease diagnoses?
Investigation 6: How are AI-based techniques helping doctors in diagnosing diseases?
3 Artificial intelligence in disease diagnosis
Detecting any irresistible ailment is nearly an afterward movement and forestalling its spread requires ongoing data and examination. Hence, acting rapidly with accurate data tosses a significant effect on the lives of individuals around the globe socially and financially (Minaee et al. 2020). The best thing about applying AI in health care is to improve from gathering and processing valuable data to programming surgeon robots. This section expounds on the various techniques and applications of artificial intelligence, disease symptoms, diagnostics issues, and a framework for disease detection modelling using learning models and AI in healthcare applications (Kumar and Singla 2021).
3.1 Framework for AI in disease detection modelling
AI describes the capability of a machine to study the way a human learns, e.g., through image identification and detecting pattern in a problematic situation. AI in health care alters how information gets composed, analysed, and developed for patient care (Ali et al. 2019).
System planning is the fundamental abstract design of the system. It includes the framework’s views, the course of action of the framework, and how the framework carries on underneath clear conditions. A solid grip of the framework design can help the client realize the limits and boundaries of the said framework. Figure 3 shows a pictorial portrayal of the ailment recognition model using utilitarian machines and profound learning classification strategies. In pre-preparing, real-world information requires upkeep and pre-preparing before being taken care of by the calculation (Jo et al. 2019). Because of the justifiable explanation, real-world data regularly contains mistakes regarding the utilized measures yet cannot practice such blunders. Accordingly, information pre-preparing takes this crude information, cycles it, eliminates errors, and spares it an extra examination. Information experiences a progression of steps during pre-handling (Chen et al. 2019a, b): Information is purged by various strategies in information cleaning. These strategies involve gathering information, such as filling the information spaces that are left clear or decreasing information, such as the disposal of commas or other obscure characters. In information osmosis, the information is joined from a combination of sources. The information is then amended for any blend of mistakes, and they are quickly taken care of. Information Alteration: Data in this progression is standardized, which depends upon the given calculation. Information standardization can be executed utilizing several ways (Nasser et al. 2019). This progression is obligatory in most information mining calculations, as the information wants to be as perfect as possible. Information is then mutual and developed. Information Lessening: This progression in the strategy centers to diminish the information to more helpful levels. Informational collection and test information: The informational collection is segregated into parts preparing and testing informational indexes. The preparation information is utilized to gauge the actual examples of the data (Sarao et al. 2020). Equivalent to information needed for preparing and testing, experimental data is often replicated from a similar informational index. After the model has been pre-handled, the jiffy step is to test the accuracy of the framework. Systematic model: Analytical displaying strategies are utilized to calculate the probability of a given occurrence function given commitment factors, and it is very productive in illness expectation. It tends to imagine what the individual is experiencing in light of their info indications and prior determinations (Keenan et al. 2020; Rajalakshmi et al. 2018).

Framework for disease detection system
3.2 Medical imaging for diseases diagnosis
Clinical Imaging is seen to assign the arrangement of procedures that produce pictures of the inside part of the body. The procedure and cycles are used to take pictures of the human body for clinical purposes, such as uncovering, analysing, or looking at an injury, brokenness, and pathology (Bibault et al. 2020). Computed tomography (CT) scan outputs are great representations of helpful indicative imaging that encourages exact conclusion, mediation, and evaluation of harms and dysfunctions that actual advisors address consistently (Chen et al. 2017). Additional contemplates demonstrate overuse of Imaging, for example, X-rays or magnetic resonance imaging (MRI) for intense and complicated work, as shown in Table 2.
3.3 Symptoms of diseases and challenges to diagnostics
The disease may be severe, persistent, cruel, or benign. Of these terms, persistent and severe have to do with the interval of a disease, lethal and begin with the potential for causing death. Additionally, different manifestations that may be irrelevant could post the warnings for more restorative severe illness or situation. The followings are a couple of diseases with their sign and indications for events:
-
Heart assault signs incorporate hurt, nervousness, crushing, or feeling of breadth in the focal point of the chest that endures more than a couple of moments; agony or anxiety in different territories of the chest area; succinctness of breath; cold perspiration; heaving; or unsteadiness (Aggarwal et al. 2020).
-
Stroke signs incorporate facial listing, arm shortcoming, the intricacy with discourse, quickly creating happiness or equalization, unexpected absence of sensation or weak point, loss of vision, puzzlement, or agonizing torment (Lukwanto et al. 2015).
-
Reproductive wellbeing manages the signs that develop the issues such as blood misfortune or spotting between periods; tingling, copying, disturbance at genital region; agony or disquiet during intercourse; genuine or sore feminine dying; extreme pelvic/stomach torment; strange vaginal release; the sentiment of totality in the lower mid-region; and customary pee or urinary weight (Kather et al. 2019).
-
Breast issue side effects include areola release, abnormal bosom delicacy or torment, bosom or areola skin changes, knot or thickening in or close to bosom or in the underarm zone (Memon et al. 2019).
-
Lung issue side effects include hacking of blood, succinctness of breath, difficult breathing, consistent hack, rehashed episodes of bronchitis or pneumonia, and puffing (Ma et al. 2020).
-
Stomach or stomach-related issue manifestations incorporate rectal dying, blood in the stool or dark stools, changes in gut properties or not having the option to control guts, stoppage, loose bowels, indigestion or heartburn, or spewing blood (Kather et al. 2019).
-
Bladder issue manifestations include confounded or excruciating pee, incessant pee, loss of bladder control, blood in pee, waking routinely to pee around evening time to pee or wetting the bed around evening time, or spilling pee (Shkolyar et al. 2019).
-
Skin issue indications remember changes for skin moles, repetitive flushing and redness of face and neck, jaundice, skin sores that do not disappear or re-establish to wellbeing, new development or moles on the skin, and thick, red skin with bright patches (Rodrigues et al. 2020).
-
Emotional issues include nervousness, sadness, weariness, feeling tense, flashbacks and bad dreams, lack of engagement in daily exercises, self-destructive musings, mind flights, and fancies (Krittanawong et al. 2018).
-
Headache issues indications (excluding ordinary strain cerebral pains) incorporate migraines that please unexpectedly, “the most noticeably awful migraine of your life”, and cerebral pain connected with extreme energy, queasiness, heaving, and powerlessness to walk (Mueller 2020).
Above, we have described the variety of illness signals and their symptoms. In contrast, illness recognition errors in medication are reasonably regular, can have a stringent penalty, and are only now the foundation to materialize outstandingly in patient safety. Here we have critical issues for various diagnostic types while detecting the particular diseases (Chuang 2011; Park et al. 2020).
-
Analysis that is accidentally deferred wrong, or on the other hand, missed as decided from a definitive delight of more amazing data.
-
Any fault or malfunction in the analytical course which is essential to a missed finding or a conceded conclusion comprises a breakdown in occasional admittance to mind; elicitation or comprehension of side effects, images, research facility result; detailing and weighing of difference investigation; and ideal development and strength arrangement or appraisal.
3.4 Healthcare applications
The healthcare system has long been an early adopter of generally innovative technologies. Today, artificial intelligence and its subset machine and deep learning are on their way to becoming a mean element in the healthcare system, from creating new health check actions to treat patient records and accounts. One of the maximum burdens physician practices today is the association and performance of organizational tasks (Fukuda et al. 2019). By automating them, healthcare institutions could help resolve the trouble and allow physicians to do their best, i.e., spend more time with patients. The following are the details of the artificial intelligence techniques in healthcare applications as shown in Table 3:
4 Reported work
This section highlights the best finding for different diseases with their diagnosis methods via machine and deep learning algorithms. It covers the extensive survey on various diseases such as alzheimer’s, cancer, diabetes, chronic, heart disease, tuberculosis, stroke and cerebrovascular, hypertension, skin and liver disease (Chui et al. 2020).
4.1 Diagnosis of Alzheimer’s disease
Alzheimer’s is a disease that worsens the dementia symptoms over several years (Zebene et al. 2019). During its early stage, it affects memory loss, but in the end, it loses the ability to carry the conservation and respond to the environment. Usyal et al. (2020) decided on the analysis of dementia in Alzheimer’s through investigating neuron pictures. They utilized the alzheimer’s disease neuroimaging initiative convention that comprises T1 weighted magnetic resonance information for finding. The prescient shows the precision estimated the characterization models, affectability, and explicitness esteem. Ljubic et al. (2020) presented the method to diagnose Alzheimer’s disease from electronic medical record (EMR) data. The results acquired showed the accuracy by 90% on using the SCRL dataset. Soundarya et al. (2020) proposed the methodology in which description of shrink brain tissue is used for the ancient analysis of Alzheimer’s disease. They have implemented various machine and deep learning algorithms. The deep algorithm has been considered the better solution provider to recognize the ailment at its primary stage with reasonable accuracy. Park et al. (2020) used a vast range of organizational health data to test the chance of machine learning models to expect the outlook occurrence of Alzheimer’s disease. Lin et al. (2019) proposed a method that used the spectrogram features extracted from speech data to identify Alzheimer’s disease. The system used the voice data collected via the internet of things (IoT) and transmitted to the cloud server where the original data is stored. The received data is used for training the model to identify the Alzheimer’s disease symptoms.
As seen in Fig. 4, (Subasi 2020) proposed a broad framework for detecting Alzheimer’s illness using AI methods. The learning process is the process of optimizing model parameters using a training dataset or prior practice. Learning models can be predictive, predicting the future, descriptive, collecting data from input data sources, and combining them. Two critical stages are performed in machine learning and deep learning: pre-processing the vast input and improving the model. The second phase involves effectively testing the learning model and resembling the answer. Oh et al. (2019) offered a technique for demonstrating the end-to-end learning of four binary classification problems using a volumetric convolutional neural network form. The trials are performed on the ADNI database, and the results indicated that the suggested technique obtained an accuracy of 86.60% and a precision of 73.95%, respectively. Raza et al. (2019) proposed a unique AI-based examination and observation of Alzheimer’s disorder. The analysis results appeared at 82% improvement in contrast with notable existing procedures.

Alzheimer’s disease detection using artificial intelligence techniques (Subasi 2020)
Additionally, above 95% precision is accomplished to order the exercises of everyday living, which are very reassuring regarding checking the action profile of the subject. Lodha et al. (2018) used a machine-learning algorithm to process the data obtained by neuroimaging technologies to detect Alzheimer’s in its primitive stage. It uses various algorithms like support vector machine (SVM), gradient boosting, K-nearest neighbour, Random forest, a neural network that shows the accuracy rate 97.56, 97.25, 95.00, 97.86, 98.36, respectively. Lei et al. (2020) state that to evaluate Alzheimer’s ailment, a clinical score forecast using neuroimaging data is incredibly profitable since it can adequately reveal the sickness status. The proposed structure comprises three sections: determination dependent on joint learning, highlight encoding dependent on profound polynomial arrange and amass learning for relapse through help vector relapse technique. Jo et al. (2019) performed the deep learning approach and neuroimaging data for the analytical classification of Alzheimer’s disease. Autoencoder for feature selection formed accuracy up to 98.8% and 83.7% for guessing conversion from mild cognitive impairment, a prodromal stage of Alzheimer’s disease.
A deep neural network uses neuroimaging data without pre-processing for feature collection that yields accuracies up to 96.0% for Alzheimer’s disease categorization and 84.2% for the medical council of India conversion problems (Oomman et al. 2018). Chen et al. (2017) hypothesized the combination of diffusivity and kurtosis in diffusion kurtosis imaging to increase the capacity of diffusion kurtosis imaging in detecting Alzheimer’s disease. The method was applied on the 53 subjects, including 27 Alzheimer’s patients, which provides an accuracy of 96.23%. Janghel et al. (2020) used a convolution neural network to improve classification accuracy. They demonstrated a deep learning technique for identifying Alzheimer’s disease using data from the Alzheimer’s disease neuroimaging initiative database, which included magnetic resonance imaging and positron emission tomography scan pictures of Alzheimer’s patients, as well as an image of a healthy individual. The experiment attained an average classification accuracy of 99.95% for the magnetic resonance imaging dataset and 73.46% for the positron emission tomography scan dataset. Balaji et al. (2020) presented the gait classification system based on machine learning to help the clinician diagnose the stage of Parkinson’s disease. They used four supervised machine learning algorithms: decision tree, support vector machine, ensemble classifier, and Bayes’ classifier, which are used for statistical and kinematic analysis that predict the severity of Parkinson’s disease.
4.2 Diagnosis of cancer disease
Artificial Intelligence methods can affect several facets of cancer therapy, including drug discovery, drug development, and the clinical validation of these drugs. Pradhan et al. (2020) evaluated several machine learning algorithms which are flexible for lung cancer recognition correlated with the internet of things. They reviewed various papers to predict different diseases using a machine learning algorithm. They also identified and depicted various research directions based on the existing methodologies. Memon et al. (2019) proposed an AI calculation-based symptomatic framework which adequately grouped the threatening and favorable individuals in the climate of the internet of things. They tried the proposed strategy on the Wisconsin Diagnostic Breast Cancer. They exhibited that the recursive element determination calculation chose the best subset of highlights and the classifier support vector machine that accomplished high order precision of 99% and affectability 98%, and Matthew’s coefficient is 99%. Das et al. (2019) proposed another framework called the watershed Gaussian-based profound learning method to depict the malignant growth injury in processed tomography pictures of the liver. They took a test of 225 pictures which are used to build up the proposed model. Yue et al. (2018) reviewed the machine learning techniques that include artificial neural networks, support vector machines, decision trees, and k-nearest neighbor for disease diagnosis. The author has investigated the breast cancer-related applications and applied them to the Wisconsin breast cancer database. Han et al. (2020) focused on the research and user-friendly design of an intelligent recommendation model for cancer patients’ rehabilitation schemes. Their prediction also achieved up to 92%. Rodrigues et al. (2020) proposed utilizing the move learning approach and profound learning approach in an IoT framework to help the specialists analyse common skin sores, average nevi, and melanoma. This investigation utilized two datasets: the first gave by the International Skin Imaging Collaboration at the worldwide Biomedical Imaging Symposium. The DenseNet201 extraction model, joined with the K nearest neighbor classifier, accomplished an exactness of 96.805% for the International Society for Bioluminescence and Chemiluminescence - International Standard Industrial Classification dataset. Huang et al. (2020) reviewed the literature on the application of artificial intelligence for cancer diagnosis and prognosis and demonstrated how these methods were advancing the field. Kather et al. (2019) used deep learning to mine clinically helpful information from histology. It can also predict the survival and molecular alternations in gastrointestinal and liver cancer. Also, these methods could be used as an inexpensive biomarker only if the pathology workflows are used. Kohlberger et al. (2019) built up a convolution neural organization to restrict and measure the seriousness of out-of-fold districts on digitized slides. On contrasting it and pathologist-reviewed center quality, ConvFocus accomplished Spearman rank coefficients of 0.81 and 0.94 on two scanners and replicated the typical designs from stack checking. Tschandl et al. (2019) build an image-based artificial intelligence for skin cancer diagnosis to address the effects of varied representations of clinical expertise and multiple clinical workflows. They also found that excellent quality artificial intelligence-based clinical decision-making support improved diagnostic accuracy over earlier artificial intelligence or physicians. It is observed that the least experienced clinicians gain the most from AI-based support. Chambi et al. (2019) worked on the volumetric Optical coherence tomography datasets acquired from resected cerebrum tissue example of 21 patients with glioma tumours of various stages. They were marked as either non-destructive or limo-invaded based on histopathology assessment of the tissue examples. Unlabelled Optical coherence tomography pictures from the other nine patients were utilized as the approval dataset to evaluate the strategy discovery execution. Chen et al. (2019a, b) proposed a cost-effective technique, i.e., ARM (augmented reality microscope), that overlays artificial intelligence-based information onto the current view of the model in real-time, enabling a flawless combination of artificial intelligence into routine workflows. They even anticipated that the segmented reality microscope would remove the barrier to using AI considered to enhance the accuracy and efficiency of cancer analysis.
4.3 Diabetes detection
Diabetes Mellitus, also known as diabetes, is the leading cause of high blood sugar. AI is cost-effective to reduce the ophthalmic complications and preventable blindness associated with diabetes. This section covers the study of various researchers that worked on detecting diabetes in patients (Chaki et al. 2020). Kaur and Kumari (2018) used machine learning models on Pima Indian diabetes dataset to see patterns with risk factors with the help of the R data manipulation tool. They also analyse d five predictive models using the R data manipulation tool and support vector machine learning algorithm: linear kernel support vector machine, multifactor dimensionality reduction, and radial basis function.
As shown in Fig. 5, blood glucose prediction has been categorized in three different parts: physiology-based, information-driven, and hybrid-based. Woldaregy et al. (2019) developed a compact guide in machine learning and a hybrid system that focused on predicting the blood glucose level in type 1 diabetes. They mentioned various machine learning methods crucial to regulating an artificial pancreas, decision support system, blood glucose alarm applications. They had also portrayed the knowledge about the blood glucose predictor that gave information to track and predict blood glucose levels as many factors could affect the blood glucose levels like BMI, stress, illness, medications, amount of sleep, etc. Thus blood glucose prediction provides the forecasting of an individual’s blood glucose level based on the past and current history of the patient to give an alarm to delay any complications. Chaki et al. (2020) provided detailed information to detect diabetes mellitus and self-management techniques to prove its importance to the scientists that work in this area. They also analyse d and diagnosed diabetes mellitus via its dataset, pre-processing techniques, feature extraction methods, machine learning algorithms, classification, etc. Mercaldo et al. (2017) proposed a method to classify diabetes-affected patients using a set of characteristics selected by a world health organization and obtained the precision value and recall value 0.770 and 0.775, respectively, with the help of the Hoeffding tree algorithm. Mujumdar et al. (2019) proposed the model for prediction, classification of diabetes, and external factors like glucose, body mass index, insulin, age, etc. They also analyse d that classification accuracy proved to be much more efficient with the new dataset than their used dataset. Kavakiotis et al. (2017) conducted a systematic review regarding the machine learning applications, data mining techniques, and tools used in the diabetes field to showcase the prediction and diagnosis of diabetes, its complications, and genetic conditions and situation, including the physical condition care management. After the in-depth search, it had been found that supervised learning methods characterized 85%, and the rest, 15%, were characterized by unsupervised learning methods. Aggarwal et al. (2020) demonstrated the non-linear heart rate variability in the prediction of diabetes using an artificial neural network and support vector machine. The author computed 526 datasets and obtained the classification accuracy of 90.5% with a support vector machine. Besides that, they evaluated thirteen non-linear heart rate variability parameters for the training and testing of artificial neural networks. Lukmanto et al. (2015) worked on many diabetes mellitus patients to provide an advantage for researchers to fight against it. Their main objective was to leverage fuzzy support vector machine and F-score feature selection to classify and detect diabetes mellitus. The methodology is applied to the Pima Indian Diabetes dataset, where they got an accuracy of 89.02% to predict the diabetes mellitus patients. Wang et al. (2017) proposed a weighted rank support vector machine to overcome the imbalanced problem seen during the daily dose system of drugs, leading to poor prediction results. They also employed the area under the curve (AUC) to show the model’s effectiveness and improved the average precision of their proposed algorithm. Carter et al. (2018) showcased the performance of 46 different machine learning models compared on re-sampled trained and tested data. The model obtained the area under the curve of 0.73 of training data and 0.90 of tested data. Nazir et al. (2019) proposed a technique to minutely detect the diabetic retinopathy’s different stages via tetragonal local octa pattern features that are further classified by extreme machine learning. For classifying periodic heart rate variability signals and diabetes, Swapna et al. (2018) presented a deep learning architecture. The authors used long short term memory, a convolution neural network, to extract the dynamic features of heart rate variability. They achieved an accuracy of 95.7% on using electrocardiography signals along with the support vector machine classification.

Blood glucose prediction approaches (Woldaregy et al. 2019)
4.4 Diagnose chronic diseases
Researchers have shown that artificial intelligence helps in the streamlining care of chronic diseases. Therefore, various machine learning algorithms are developed to identify patients at higher risk of chronic disease. The other techniques based on AI are stated below (Jain et al. 2018).
Jain et al. (2018) presented a survey to showcase feature choice and arrangement methods to analyse and anticipate the constant illnesses. They utilized dimensionality decrease strategies to improve the presentation of AI calculation. To put it plainly, they introduced different component determination techniques and their inalienable points of interest and impediments. He et al. (2019) proposed a kernel-based structure for training the chronic illness detector to forecast and track the disease’s progression. Their approach was based on an enhanced version of a structured output support vector machine for longitudinal data processing. Tang et al. (2020) utilized deep residual networks to identify chronic obstructive pulmonary disease automatically. After gathering data from the PanCad project, which includes ex-smokers and current smokers at high risk of lung cancer, the residual network was trained to diagnose chronic obstructive pulmonary disease using computed topography scans. Additionally, they ran three rounds of cross-validation on it. With the help of three-fold cross-validation, the experiment had an area under the curve of 0.889. Ma et al. (2020) proposed the heterogeneous changed artificial neural organization to identify, divide, and determine persistent renal disappointment utilizing the web of medical things stage. The proposed strategy was named uphold vector machine and multilayer perceptron alongside the back engendering calculation. They used ultrasound images and later performed segmentation in that image. Especially in Kidney segmentation, it performed very well by achieving high results. Aldhyani et al. (2020) proposed the system that was used to increase the accuracy in detecting chronic disease by using machine learning algorithms. The machine learning methods such as Naïve Bayes, support vector machine, K nearest neighbour, and random forest were presented and compared. They also used a rough k-means algorithm to figure out the ambiguity in chronic disease to improve its performance. The Naïve Bayes method and RKM achieved an accuracy of 80.55% for diabetic disease, the support vector machine achieved 100% accuracy for kidney disease, and the support vector machine achieved 97.53% for cancer disease. Chui and Alhalabi (2017) reviewed the chronic disease diagnosis in smart health care. They provide a summarized view of optimization algorithms and machine learning algorithms. The authors also gave information regarding Alzheimer’s disease, dementia, tuberculosis, etc., followed by the challenges during the deployment phase of the disease diagnosis. Nam et al. (2019) introduced the internet of things and digital biomarkers and their relationships to artificial intelligence and other current trends. They have also discussed the role of artificial intelligence in the internet of things for chronic disease detection. Battineni et al. (2020) reviewed the applications of predictive models of machine learning to diagnose chronic disease. After going through 453 papers, they selected only 22 studies from where it was concluded that there were no standard methods that would determine the best approach in real-time clinical practice. The commonly used algorithms were support vector machine, logistic regression, etc. Wang et al. (2018) analyse d chronic kidney disease using machine learning techniques based on chronic kidney disease dataset and performed ten-fold cross-validation testing. The dataset had been pre-processed for completing and normalizing the missing data. They achieved the detection accuracy of 99% and were further tested using four patient data samples to predict the disease. Kim et al. (2019) indicated the constant sicknesses in singular patients that utilized a character repetitive neural organization to regard the information in each class as a word, mainly when an enormous bit of its information esteem is absent. They applied the Char-recurrent neural network to characterize the Korea National Health and Nutrition Examination Survey cases. They indicated the aftereffects of higher precision for the Char-recurrent neural network than for the customary multilayer perceptron model. Ani et al. (2017) proposed a patient monitoring system for stroke-affected people that reduced future recurrence by alarming the doctor and provided the data analytics and decision-making based on the patient’s real-time health parameters. That helped the doctors in systematic diagnosis followed by tailored treatment of the disease.
4.5 Heart disease diagnosis
Researchers suggest that artificial intelligence can predict the possible periods of death for heart disease patients. Thus multiple algorithms have been used to predict the heart rate severity along with its diagnosis. Escamila et al. (2019) proposed a dimensionality decrease strategy to discover the highlights of coronary illness utilizing the highlight determination procedure. The dataset used was the UCIrvine artificial intelligence vault called coronary illness which contains 74 highlights. The most remarkable precision was accomplished by the chi-square and head segment investigation alongside the irregular woods classifier. Tuli et al. (2019) proposed a Health fog framework to integrate deep learning in edge computing devices and incorporate it into the real-life application of heart detecting disease. They consisted of the hardware and software components, including body area sensor network, gateway, fogbus module, data filtering, pre-processing, resource manager, deep learning module, and ensembling module. The health fog model was an internet of things-based fog enabled model that can help effectively manage the data of heart patients and diagnose it to identify the heart rate severity.
George et al. (2018) aimed to describe the obstacles Indian nurses face in becoming active and valued members of the cardiovascular healthcare team as cardiovascular disease imposed substantial and increasing physical, psychological, societal, and financial burdens. As shown in Fig. 6, there are numerous possible facts for health intelligent mediations to support helping cardiovascular health and decreasing hazard for cardiovascular disease. So the focus has started on the inhibition of cardiovascular disease and, more importantly, on the advancement of cardiovascular health. Several findings revealed that depression is connected with inferior cardiovascular health between adults without cardiovascular disease.

Cardiovascular health promotion and disease prevention (George et al. 2018)
Haq et al. (2018) created a system based on machine learning to diagnose the cardiac disease guess using its dataset and worked on seven prominent feature learning-based algorithms. It was also observed that the machine learning-based decision support system assisted the doctors in diagnosing the heart patients effectively. Khan and Member (2020) proposed a framework to estimate the cardio disease using a customized deep convolution network for categorizing the fetched sensor information into the usual and unusual state. Their results demonstrated that if there would be the utmost amount of records, the multi-task cascaded convolution neural network achieved an accuracy of 98.2%. Ahmed (2017) explained the architecture for heart rate and other techniques to understand using machine learning algorithms such as K nearest neighbour classification to predict the heart attack during collecting heart rate datasets. The author also mentioned the six data types predicting heart attack in three different levels (Patel 2016). The dataset used consists of 303 instances and 76 attributes. They worked on a technique that could reduce the number of deaths from heart diseases. They compared various decision tree algorithms to present the heart disease diagnosis using Waikato Environment for Knowledge Analysis. They aimed to fetch the hidden patterns by using data mining techniques linked to heart disease to predict its presence. Saranya et al. (2019) proposed a cloud-based approach based on sensors for an automated disease predictive system to calculate various parameters of patients like blood pressure, heartbeat rate, and temperature. As per their knowledge, this method could reduce the time complexity of the doctor and patient in providing medical treatment quickly. The best part was that anyone could access it from anywhere. Isravel et al. (2020) presented a pre-processing approach that might enhance the accuracy in identifying the electrocardiographic signals. They evaluated the classification using different classifying algorithms such as K nearest neighbour, Naïve Bayes, and Decision tree to detect normal and irregular heartbeat sounds. Also, after trying, it was discovered that pre-processing approach increased the performance of classifying algorithms. The devices utilized for IoT set up were the LM35 sensor, Pulse sensor, AD8232 electrocardiographic sensor, and Arduino Uno. Thai et al. (2017) proposed a new lightweight method to remove the noise from electrocardiographic signals to perform minute diagnosis and prediction. Initially, they worked on the Sequential Recursive algorithm for the transformation of signals into digital format. The same was sent to the Discrete Wavelet Transform algorithm to detect the peaks in the data for removing the noises. Then features were extracted from the electrocardiographic dataset from Massachusetts Institute of Technology-Beth Israel Hospital to perform diagnosis and prediction and remove the redundant features using Fishers Linear Discriminant. Nashif et al. (2018) proposed a cloud-based heart disease prediction system for detecting heart disease using machine learning models derived from Java Based Open Access Data Mining Platform, Waikato Environment for Knowledge Analysis. They got an accuracy level of 97.53% using a support vector machine with 97.50% sensitivity and 94.94% specificity. They used an efficient software tool that trained the large dataset and compared multiple machine learning techniques. The smartphone used to detect and predict heart disease based on the information acquired from the patients. Hardware components are used to monitor the system continuously. Babu et al. (2019) aimed to determine whether the heart attack could occur using hereditary or not. Thus to work on it, initially, they collected and compared the previous data of parents with their child dataset to find the prediction and accurate values. It could help them to determine how healthy the child is. The authors used different parameters to show the dependent and independent parameters to find whether the person gets a heart attack.
4.6 Tuberculosis disease detection
AI is placed as an answer for aid in the battle against tuberculosis. Computerized reasoning applications in indicative radiology might have the option to give precise methods for recognizing the infections for low pay countries. Romero et al. (2020) performed the classification tree analysis to reveal the associations between predictors of tuberculosis in England. They worked on the American Public Health Association data ranging from demographic herd properties and tuberculosis variables using Sam Tuberculosis management. They used a machine-learning algorithm, performed data preparation, data reduction, and data analysis, and finally got the results. Horvath et al. (2020) performed the automatic scanning and analysis on 531 slides of tuberculosis, out of which 56 were from the positive specimen. They also validated a scanning and analysis system to combine fully automated microscopy using deep learning analysis. Their proposed system achieved the highest sensitivity by detecting 40 out of 56 positive slides. Sathitratanacheewin et al. (2020) developed a convolution neural network model using tuberculosis. They used a specified chest X-ray dataset taken from the national library of medical Shenzhen no. 3 hospitals and did its testing with a non-tuberculosis chest X-ray dataset taken from the national institute of health care and center. The deep convolution neural network model achieved the region of curve area under the curve by 0.9845 and 0.8502 for detecting tuberculosis and the specificity 82% and sensitivity of 72%. Bahadur et al. (2020) proposed an automatic technique to detect the abnormal chest X-ray images that contained at least one pathology such as infiltration, fibrosis, pleural effusion, etc., because of tuberculosis. This technique is based on a hierarchical structure for extracting the feature where feature sets are used in two hierarchy levels to group healthy and unhealthy people. The authors used 800 chest X-ray images taken from two public datasets named Montgomery and Shenzhen. López-Úbeda et al. (2020) explored the machine learning methods to detect tuberculosis in Spanish radiology reports. They also mentioned the deep learning classification algorithms with the purpose of its evaluation and comparison and to carry such a task. The authors have used the data of 5947 radiology reports collected from high-tech media. Ullah et al. (2020) presented the study of Raman Spectroscopy and machine learning based on principal component analysis and hierarchical component analysis to analyse tuberculosis either in positive form or negative form. They also showed Raman results which indicated the irregularities in the blood composition collected from tuberculosis-negative patients. Panicker et al. (2018) introduced the programmed technique for the location of tuberculosis bacilli from tiny smear pictures. They performed picture binarization and grouping of distinguished districts utilizing convolution neural organization. They did an assessment utilizing 22 sputum smear minuscule pictures. The results demonstrated 97.13% review, 78.4% accuracy, 86.76% F-score for predicting tuberculosis. Lai et al. (2020) compared the artificial neural network outcomes, support vector machine, and random forest while diagnosing anti-tuberculosis drugs on Taipei Medical University Wanfang Hospital patients. They selected the features via univariate risk factor analysis and literature evaluation. The authors achieved the specificity by 90.4% and sensitivity of 80%. Gao et al. (2019) investigated the applications of computed topography pulmonary images to detect tuberculosis at five levels of severity. They proposed a deep Res Net to predict the severity scores and analyse the high severity probability. They also calculate overall severity probability, separate probabilities of both high severity and low severity forces. Singh et al. (2020) worked to discover tuberculosis sores in the lungs. They proposed a computerized recognition strategy utilizing a profound learning technique known as Antialiased Convolution Neural Network proposed by Richard Zhang. Their dataset included 3D computed topography pictures, which were cut into 2D pictures. They applied division on each cutting picture utilizing UNet and Link net design.
4.7 Stroke and cerebrovascular disease detection
AI can analyse and detect stroke signs in medical images as if the system suspects a stroke in the patient. It immediately gives the signal to the patient or doctor. Researchers have proposed various methodologies to showcase the impact of AI in stroke and cerebrovascular detection (Singh et al. 2009). O’Connell et al. (2017) assessed the diagnostic capability and temporal stability for the detection of stroke. They observed the mostly identical patterns between the stroke patients and controls across the ten patients. They achieved the specificity and sensitivity of 90% across the research. Labovitz et al. (2017) stated the use of AI for daily monitoring of patients for the identification and medication. They achieved the improvement by 50%on plasma drug concentration levels. Abedi et al. (2020) also presented a framework to build up the decision support system using an artificial neural network, which improved patient care and outcome. Singh et al. (2009) compared the different methods to predict stroke on the cardiovascular health study dataset. They also used the decision tree algorithm for the feature selection process, principal component analysis to reduce the classification algorithm’s dimension, and a backpropagation neural network. Biswas et al. (2020) introduced an AI-based system for the location and estimation of carotid plaque as carotid intima-media thickness for the same and solid atherosclerotic carotid divider discovery and plaque estimations.
4.8 Hypertension disease detection
Researchers have found that AI has been able to diagnose hypertension by taking input data from blood pressure, demographics, etc. Krittanawong et al. (2018) summarized the review about the recent computer science and medical field advancements. They also illustrated the innovative approach of artificial intelligence to predict the early stages of hypertension. They also stated that AI plays a vital role in investigating the risk factors for hypertension. However, on the side, it has also been restricted by researchers because of its limitations in designing, etc. Arsalan et al. (2019) conducted the experiments using three publicly available datasets as digitized retinal imagery for vessel extraction (DRIVE), structured analysis of retina (STARE) for hypertension detection. They achieved the accuracy for all datasets with sensitivity, specificity, area under the curve, and accuracy of 80.22%, 98.1%, 98.2%, 96.55%, respectively. Kanegae et al. (2020) used machine learning techniques to validate the prediction of risk for new-onset hypertension. They used data in a split form for the model construction and development and validation to test its performance. The models they used were XGBoost and ensemble, in which the XGBoost model was considered the best predictor because it was systolic blood pressure nature during cardio ankle vascular. Figure 7 shows the structure of heart during its normal phase as well as in hypertension phase. When the human heart is in hypertension phase, its pulmonary arteries gets constricted because of which the right ventricle did not get the blood in to the lungs.

Pulmonary hypertension (Kanegae et al. 2020)
Koshimizu et al. (2020) has also described artificial intelligence in pulse the executives, which was utilized to foresee the chance of circulatory strain utilizing enormous scope information. The authors also focused on the measure that was used to control blood pressure using an artificial neural network. In a nutshell, they were trying to prove that an artificial neural network is beneficial for high blood pressure organization and can also use it to create medical confirmation for the realistic organization of hypertension. Mueller et al. (2020) stated that using artificial analytic tools to the large dataset based on hypertension would generate questionable results and would also miss treatments and the potential targets. The author also stated that the vision of hypertension would be challenging to achieve and doubtlessly not happen in the future. Chaikijuraja et al. (2020) also noted the merits of using artificial intelligence to detect hypertension as artificial intelligence can recognize hypertension’s risk factors and phenotypes.
Moreover, it is used to interpret data from randomized trials that contained blood pressure targets associated with cardio vascular outcomes. Kiely et al. (2019) investigated the prescient model dependent on the medical care assets that could be sued to screen huge populaces to distinguish the patients at great danger of pneumonic blood vessel hypertension. They took the information of 709 patients from 2008 to 2016 with pneumonic blood vessel hypertension and contrasted it and separated associate of 2,812,458 who was delegated non-aspiratory blood vessel hypertension just as the prescient model was created and approved by utilizing cross approval. Kwon et al. (2020) did the past group learning of information taken on or after successive diseased people from two health care sectors to predict pulmonary hypertension using electrocardiography with the help of artificial intelligence. Sakr et al. (2018) assessed and analyse d AI strategies, such as Logit Boost, Bayesian Network Classifier, locally weighted Naïve Bayes, counterfeit neural organization, Support Vector Machine, and Random Tree Forest foresee the people to recognize hypertension. Thus, AI provides insights for hypertension healthcare and implements prescient, customized, and pre-emptive methodologies in clinical practice.
4.9 Skin disease diagnosis
Researchers have developed an AI system that can precisely group cutaneous skin problems and fill in as an auxiliary instrument to improve the demonstrative exactness of clinicians. Chakraborty et al. (2017) proposed a neural-based location technique for various skin disorders. They utilized two infected skin pictures named Basel Cell Carcinoma and Skin Angioma. Non-overwhelming arranging hereditary calculation is used to prepare the counterfeit neural organization, contrasted with the neural network particle swarm optimization classifier and neural network Caesarean Section classifier. Zaar et al. (2020) collected the clinical images of skin disease from the department of Dermatology at the Sahlgrenska University, where artificial intelligence algorithms had been used for the classification, thereby achieving the diagnosis accuracy by 56.4% for the top five suggested diseases. Kumar et al. (2019) used a dual-stage approach that combined computer vision and machine learning to evaluate and recognize skin diseases. During training and testing of the diseases, the method produced an accuracy of up to 95%. Kolkur et al. (2018) developed a system that identified skin disease based on input symptoms. They collected the data of the symptoms of ten skin diseases and got 90% above accuracy.
4.10 Liver disease detection
Researchers have found that AI can treat liver disease at its early diagnosis to work on its endurance and heal rate. Abdar et al. (2018) showed that efficient early liver disease recognition through Multilayer Perceptron Neural Network calculation depends on different choice tree calculations, such as chi-square programmed communication indicator and characterization, and relapse tree with boosting strategy. Their technique had the option to analyse and characterize the liver malady proficiently. Khaled et al. (2018) introduced an artificial neural network for the diagnosis of hepatitis virus. Protein and Histology is utilized as an info variable for the fake neural organization model, and it also showed the correct prediction of diagnosis by 93%. Spann et al. (2020) provided the strengths of machine learning tools and their potential as machine learning is applied to liver disease research, including clinical, molecular, demographic, pathological, and radiological data. Nahar and Ara (2018) explored the early guess of liver ailment using various decision tree techniques. The choice tree methods utilized were J48, Licensed Massage Therapist, Random Forest, Random Tree, REP tree, Decision Stump, and Hoeffding Trees. Their primary purpose was to calculate and compare the performances of various decision tree techniques. Farokhzad et al. (2016) used fuzzy logic for diagnosing liver sickness. Using this method, where they had two triangular membership and Gussy membership functions, they reached 79–83% accuracy.
4.11 Comparative analysis
In addition to the above mentioned reported work, the comparative analysis illustrated in Table 4 showcase the detailed information such as type of dataset, techniques, and the predicted outcomes regarding the work done by the researchers on different diseases, which in return helped the author to look for the best technique for detecting or diagnosing any particular disease.
From Table 4, we can observe that AI techniques have proven to be the best for detecting diseases with improved results. AI uses machine and deep learning models that work upon training and testing data sets so that the system can see the disease and diagnose it early. In the AI-based model, we initially need to train human beings to remember the data and provide accurate results. However, it also deals with the problem. Suppose the training data produced the incorrect analysis of disease because of insufficient information, which artificial intelligence cannot factor. As a result, it will become a horrible condition for the patients as AI cannot assure us whether the prediction regarding disease detection is accurate.
On assaying the accuracy of algorithms in diagnosing the disease, deep learning classifiers have dominated over machine learning models in the field of disease diagnosis. Deep learning models have proved to be best in terms of scalp disease by 99%, Alzheimer disease by 96%, thyroid disease by 99%, 96% in skin disease, 99.37% in case of Arrhythmia disease, 95.7% in diabetic disease, while as machine learning models achieved 89% in diabetic disease, 88.67% in tuberculosis, 86.84% in Alzheimer disease, etc.
5 Discussion
We have presented recently published research studies that employed AI-based Learning techniques for diagnosing the disease in the current review. This study highlights research on disease diagnosis prediction and predicting the post-operative life expectancy of diseased patients using AI-based learning techniques.
Investigation 1: Why do we need AI?
We know that AI is the simulation of human processes by machines (computer systems) and that this simulation includes learning, reasoning, and self-correction. We require AI since the amount of labour we must perform is rising daily. As a result, it’s a good idea to automate regular tasks. It conserves the organization’s staff and also boosts production (Vasal et al. 2020).
In terms of the healthcare industry, AI in health refers to a set of diverse technologies that enable robots to detect, comprehend, act, and learn1 to execute administrative and clinical healthcare activities. AI has the potential to transform healthcare by addressing some of the industry’s most pressing issues. For example, AI can result in improved patient outcomes and increased productivity and efficiency in care delivery (Gouda et al. 2020). It can also enhance healthcare practitioners’ daily lives by spending more time caring for patients, therefore increasing staff morale and retention. In addition, it may potentially help bring life-saving medicines to market more quickly. Figure 8 shows the significance of AI in the medical field.

Importance of artificial intelligence in healthcare
Investigation 2: Why is AI important, and how is it used to analyse the disease?
The emergence of new diseases remains a critical parameter in human health and society. Hence, the advances in AI allow for rapid processing and analysis of such massive and complex data. It recommends the correct decision for over ten different diseases (as mentioned in the literature) with at least 98% accuracy.
Doctors use technologies such as computed tomography scan or magnetic resonance imaging to produce a detailed 3D map of the area that needs to be diagnosed. Later, AI technology analyse s the system-generated image using machine and deep learning models to spot the diseased area’s features in seconds. As shown in the framework section, an artificial intelligence model using machine and deep learning algorithms is initially trained with the help of a particular disease dataset (Owasis et al. 2019). The dataset is then pre-processed using data cleaning and transformation techniques so that the disease symptoms in the form of feature vectors can be extracted and further diagnosed.
Suppose doctors do not use AI techniques. In that case, it will cause a delay in treating the patients as it is tough to interpret the scanned image manually, and it also takes a considerable amount of time. But, on the other hand, it shows that an AI technique helps the patients and helps the doctors save the patient’s life by treating them as early as possible (Luo et al. 2019).
Investigation 3: What is the impact of AI in medical diagnosis?
Due to advancements in computer power, learning algorithms, and the availability of massive datasets (big data) derived from medical records and wearable health monitors. The best part of implementing AI in healthcare is that it helps to enhance various areas, including illness detection, disease classification, decision-making processes, giving optimal treatment choices, and ultimately, helping people live longer. In terms of disease diagnosis, AI has been used to enhance medical diagnosis (Chen et al. 2019a, b). For example, the technology, which is currently in use in China, may detect hazardous tumors and nodules in patients with lung cancer, allowing physicians to provide an early diagnosis rather than sending tissue samples to a lab for testing, allowing for earlier treatment (Keenan et al. 2020). Figure 9 illustrates the influence of artificial intelligence and other approaches.

Comparison between AI and other techniques
Investigation 4: Which AI-based algorithm is used in disease diagnosis?
Disease detection algorithms driven by AI demonstrated to be an effective tool for identifying undiagnosed patients with under-diagnosed, uncoded, and rare diseases. Therefore, AI models for disease detection have an ample opportunity to drive earlier diagnosis for patients in need and guide pharmaceutical companies with highly advanced, targeted diagnostics to help these patients get correctly diagnosed and treated earlier in their disease journey (Keenan et al. 2020). The research work mentioned in the literature has covered both machine and deep learning models for diagnosing the diseases such as cancer, diabetes, chronic, heart disease, alzheimer, stroke and cerebrovascular, hypertension, skin, and liver disease. Machine learning models, Random Forest Classifier, Logistic Regression, Fuzzy logics, Gradient Boosting Machines, Decision Tree, K nearest neighbour (KNN), and Support vector machines (SVM) are primarily used in literature. Among deep learning models, Convolutional Neural Networks (CNN) have been used most commonly for disease diagnosis. In addition, faster Recurrent Convolution Neural Network, Multilayer Perceptron, Long Short Term Memory (LSTM) have also been used extensively in the literature. Figure 10 displays the usage of AI-based prediction models in the literature.

Artificial intelligence-based prediction models
Investigation 5: What are the challenges faced by the researchers while using AI models in several disease diagnosis?
Although AI-based techniques have marked their significance in disease diagnosis, there are still many challenges faced by the researchers that need to be addressed.
-
i.
Limited Data size The most common challenge faced by most of the studies was insufficient data to train the model. A small sample size implies a smaller training set which does not authenticate the efficiency of the proposed approaches. On the other hand, good sample size can train the model better than the limited one (Rajalakshmi et al. 2018).
-
ii.
High dimensionality Another data-related issue faced in cancer research is high dimensionality. High dimensionality is referred to a vast number of features as compared to cases. However, multiple dimensionality reduction techniques are available to deal with this issue (Bibault et al. 2020).
-
iii.
Efficient feature selection technique Many studies have achieved exceptional prediction outcomes. However, a computationally effective feature selection method is required to eradicate the data cleaning procedures while generating high disease prediction accuracy (Koshimizu et al. 2020).
-
iv.
Model Generalizability A shift in research towards improving the generalizability of the model is required. Most of the studies have proposed a prediction model that is validated on a single site. There is a need to validate the models on multiple sites that can help improve the model’s generalizability (Fukuda et al. 2019).
-
v.
Clinical Implementation AI-based models have proved their dominance in medical research; still, the practical implementation of the models in the clinics is not incorporated. These models need to be validated in a clinical setting to assist the medical practitioner in affirming the diagnosis verdicts (Huang et al. 2020).
Investigation 6: How artificial intelligence-based techniques are helping doctors in diagnosing diseases?
AI improves the lives of patients, physicians, and hospital managers by doing activities usually performed by people but in a fraction of the time and the expense. For example, AI assists physicians in making suggestions by evaluating vast amounts of healthcare data such as electronic health records, symptom data, and physician reports to improve health outcomes and eventually save the patient’s life (Kohlberger et al. 2019). Additionally, this data aids in the improvement and acceleration of decision-making while diagnosing and treating patients’ illnesses using artificial intelligence-based approaches. Not only that, AI assists physicians in detecting diseases by utilizing complicated algorithms, hundreds of biomarkers, imaging findings from millions of patients, aggregated published clinical studies, and thousands of physicians’ notes to improve the accuracy of diagnosis.
6 Conclusion and future scope
When it comes to disease diagnosis, accuracy is critical for planning, effective treatment and ensuring the well-being of patients. AI is a vast and diverse realm of data, algorithms, analytics, deep learning, neural networks, and insights that is constantly expanding and adapting to the needs of the healthcare industry and its patients. According to the findings of this study, AI approaches in the healthcare system, particularly for illness detection, are essential. Aiming at illuminating how machine and deep learning techniques work in various disease diagnosis areas, the current study has been divided into several sections that cover the diagnosis of alzheimer’s, cancer, diabetes, chronic diseases, heart disease, stroke and cerebrovascular disease, hypertension, skin disease, and liver disease. The introduction and contribution were covered in the first section, followed by an evaluation of the quality of the work and an examination of AI approaches and applications. Later, various illness symptoms and diagnostic difficulties, a paradigm for AI in disease detection models, and various AI applications in healthcare were discussed. The reported work on multiple diseases and the comparative analysis of different techniques with the used dataset as well as the results of an applied machine and deep learning methods in terms of multiple parameters such as accuracy, sensitivity, specificity, an area under the curve, and F-score has also been portrayed. Finally, the work that assisted researchers in determining the most effective method for detecting illnesses is finished, as in future scope. In a nutshell, medical experts better understand how AI may be used for illness diagnosis, leading to more appropriate proposals for the future development of AI based techniques.
Contrary to considerable advancements over the past several years, the area of accurate clinical diagnostics faces numerous obstacles that must be resolved and improved constantly to treat emerging illnesses and diseases effectively. Even healthcare professionals recognize the barriers that must be overcome before sickness may be detected in conjunction with artificial intelligence. Even doctors do not entirely rely on AI-based approaches at this time since they are unclear of their ability to anticipate illnesses and associated symptoms. Thus much work is required to train the AI-based systems so that there will be an increase in the accuracy to predict the methods for diagnosing diseases. Hence, in the future, AI-based research should be conducted by keeping the flaw mentioned earlier in consideration to provide a mutually beneficial relationship between AI and clinicians. In addition to this, a decentralized federated learning model should also be applied to create a single training model for disease datasets at remote places for the early diagnosis of diseases.
References
Abdar M, Yen N, Hung J (2018) Improving the diagnosis of liver disease using multilayer perceptron neural network and boosted decision tree. J Med Biol Eng 38:953–965. https://doi.org/10.1007/s40846-017-0360-z
Abedi V, Khan A, Chaudhary D, Misra D, Avula V, Mathrawala D, Kraus C, Marshall KA, Chaudhary N, Li X, Schirmer CM, Scalzo F, Li J, Zand R (2020) Using artificial intelligence for improving stroke diagnosis in emergency departments: a practical framework. Ther Adv Neurol Disord. https://doi.org/10.1177/1756286420938962
Aggarwal Y, Das J, Mazumder PM, Kumar R, Sinha RK (2020) Heart rate variability features from nonlinear cardiac dynamics in identification of diabetes using artificial neural network and support vector machine. Integr Med Res. https://doi.org/10.1016/j.bbe.2020.05.001
Ahmed F (2017) An Internet of Things (IoT) application for predicting the quantity of future heart attack patients. J Comput Appl 164:36–40. https://doi.org/10.5120/ijca2017913773
Aldhyani THH, Alshebami AS, Alzahrani MY (2020) Soft clustering for enhancing the diagnosis of chronic diseases over machine learning algorithms. J Healthc Eng. https://doi.org/10.1155/2020/4984967
Alfian G, Syafrudin M, Ijaz MF, Syaekhoni MA, Fitriyani NL, Rhee J (2018) A personalized healthcare monitoring system for diabetic patients by utilizing BLE-based sensors and real-time data processing. Sensors 18(7):2183
Ali M, Tengnah J, Sooklall R (2019) A predictive model for hypertension diagnosis using machine learning techniques. Telemed Technol. https://doi.org/10.1016/B978-0-12-816948-3.00009-X
Ani R, Krishna S, Anju N, Aslam MS, Deepa OS (2017) IoT based patient monitoring and diagnostic prediction tool using ensemble classifier. In: 2017 International conference on advances in computing, communications and informatics (ICACCI), pp 1588–1593. https://doi.org/10.1109/ICACCI.2017.8126068
Ansari S, Shafi I, Ansari A, Ahmad J, Shah S (2011) Diagnosis of liver disease induced by hepatitis virus using artificial neural network. IEEE Int Multitopic. https://doi.org/10.1109/INMIC.2011.6151515
Arsalan M, Owasis M, Mahmood T, Cho S, Park K (2019) Aiding the diagnosis of diabetic and hypertensive retinopathy using artificial intelligence based semantic segmentation. J Clin Med 8:1446. https://doi.org/10.3390/jcm8091446
Babu BS, Likhitha V, Narendra I, Harika G (2019) Prediction and detection of heart attack using machine learning and internet of things. J Comput Sci 4:105–108
Bahadur T, Verma K, Kumar B, Jain D, Singh S (2020) Automatic detection of Alzheimer related abnormalities in chest X-ray images using hierarchical feature extraction scheme. Expert Syst Appl 158:113514. https://doi.org/10.1016/j.eswa.2020.113514
Balaji E, Brindha D, Balakrishnan R (2020) Supervised machine learning based gait classification system for early detection and stage classification of Parkinson’s disease. Appl Soft Comput J 94:106494
Battineni G, Sagaro GG, Chinatalapudi N, Amenta F (2020) Applications of machine learning predictive models in the chronic disease diagnosis. J Personal Med. https://doi.org/10.3390/jpm10020021
Behera R, Bala P, Dhir A (2019) The emerging role of cognitive computing in healthcare: a systematic literature review. J Med Inform 129:154–166
Bhatt V, Pal V (2019) An intelligent system for diagnosing thyroid disease in pregnant ladies through artificial neural network. In: Conference on advances in engineering science management and technology, pp 1–10. https://doi.org/10.2139/ssrn.3382654
Bibault J, Xing L (2020) Screening for chronic obstructive pulmonary disease with artificial intelligence. Lancet Digit Health 2:e216–e217. https://doi.org/10.1016/S2589-7500(20)30076-5
Biswas M, Saba L, Suri H, Lard J, Suri S, Miner M et al (2020) Two stage artificial intelligence model for jointly measurement of atherosclerotic wall thickness and plaque burden in carotid ultrasound. Comput Biol Med 123:103847. https://doi.org/10.1016/j.compbiomed.2020.103847
Carter JA, Long CS, Smith BP, Smith TL, Donati GL (2018) PT US CR. Expert Syst Appl. https://doi.org/10.1016/j.eswa.2018.08.002
Chaikijurajai T, Laffin L, Tang W (2020) Artificial intelligence and hypertension: recent advances and future outlook. Am J Hypertens 33:967–974. https://doi.org/10.1093/ajh/hpaa102
Chaki J, Ganesh ST, Cidham SK, Theertan SA (2020) Machine learning and artificial intelligence based diabetes mellitus detection and self-management: a systematic review. J King Saud Univ Comput Inf Sci. https://doi.org/10.1016/j.jksuci.2020.06.013
Chakraborty S, Mali K, Chatterjee S, Banerjee S, Roy K et al (2017) Detetction of skin disease using metaheurisrtic supported artificial neural networks. In: Industrial automation and electromechanical engineering conference, pp 224–229. https://doi.org/10.1109/IEMECON.2017.8079594
Chambi R, Kut C, Jimenez J, Jo J (2019) AI assisted in situ detection of human glioma infiltration using a novel computational method for optical coherence tomography. Clin Cancer Res 25:6329–6338
Chang W, Chen L, Wang W (2018) Development and experimental evaluation of machine learning techniques for an intelligent hairy scalp detection system. Appl Sci 8:853. https://doi.org/10.3390/app8060853
Chatterjee A, Parikh N, Diaz I, Merkler A (2018) Modeling the impact of inter hospital transfer network design on stroke outcomes in a large city. Stroke 49:370–376
Chen Y, Sha M, Zhao X, Ma J, Ni H, Gao W, Ming D (2017) Automated detection of pathologic white matter alterations in Alzheimer’s disease using combined diffusivity and kurtosis method. Psychiatry Res Neuroimaging 264:35–45. https://doi.org/10.1016/j.pscychresns.2017.04.004
Chen J, Remulla D, Nguyen J, Aastha D, Liu Y, Dasgupta P (2019a) Current status of artificial intelligence applications in urology and their potential to influence clinical practice. BJU Int 124:567–577. https://doi.org/10.1111/bju.14852
Chen P, Gadepalli K, MacDonald R, Liu Y, Dean J (2019) An augmented reality microscope with real time artificial intelligence integration for cancer diagnosis. Nat Med 25:1453–1457
Chuang C (2011) Case based reasoning support for liver disease diagnosis. Artif Intell 53:15–23. https://doi.org/10.1016/j.artmed.2011.06.002
Chui KT, Alhalabi W (2017) Disease diagnosis in smart healthcare: innovation. Technol Appl. https://doi.org/10.3390/su9122309
Chui CS, Lee NP, Adeoye J, Thomson P, Choi S-W (2020) Machine learning and treatment outcome prediction for oral cancer. J Oral Pathol Med 49:977–985. https://doi.org/10.1111/jop.13089
Connell GCO, Chantler PD, Barr TL (2017) Stroke-associated pattern of gene expression previously identified by machine-learning is diagnostically robust in an independent patient population. Genomics Data 14:47–52. https://doi.org/10.1016/j.gdata.2017.08.006
Dabowsa N, Amaitik N, Maatuk A, Shadi A (2017) A hybrid intelligent system for skin disease diagnosis. In: Conference on engineering and technology, pp 1–6. https://doi.org/10.1109/ICEngTechnol.2017.8308157
Damiani G, Grossi E, Berti E, Conic R, Radhakrishna U, Linder D, Bragazzi N, Pacifico A, Piccino R (2020) Artificial neural network allow response prediction in squamous cell carcinoma of the scalp treated with radio therapy. J Eur Acad Dermatol Venerel 34:1369–1373. https://doi.org/10.1111/jdv.16210
Das A, Acharya UR, Panda SS, Sabut S (2019) Deep learning based liver cancer detection using watershed transform and Gaussian mixture model techniques. Cogn Syst Res 54:165–175. https://doi.org/10.1016/j.cogsys.2018.12.009
Escamilla G, Hassani A, Andres E (2019) A comparison of machine learning techniques to predict the risk of heart failure. Mach Learn Paradig 1:9–26. https://doi.org/10.1007/978-3-030-15628-2_2
Farokhzad M, Ebrahimi L (2016) A novel adapter neuro fuzzy inference system for the diagnosis of liver disease. J Acad Res Comput Eng 1:61–66
Fujita S, Hagiwara A, Otuska Y, Hori M, Kumamaru K, Andica C et al (2020) Deep learning approach for generating MRA images from 3D qunatitative synthetic MRI without additional scans. Invest Radiol 55:249–256. https://doi.org/10.1097/RLI.0000000000000628
Fukuda M, Inamoto K, Shibata N, Ariji Y, Kutsana S (2019) Evaluation of an artificial system for detecting vertical root fracture on panoramic radiography. Oral Radiol 36:1–7
Gao XW, James-Reynolds C, Currie E (2019) Analysis of Alzheimer severity levels from CT pulmonary images based on enhanced residual deep learning architecture. Healthc Technol. https://doi.org/10.1016/j.neucom.2018.12.086
George A, Badagabettu S, Berra K, George L, Kamath V, Thimmappa L (2018) Prevention of cardiovascular disease in India. Clin Prev Cardiol 7:72–77. https://doi.org/10.4013/JCPC.JCPC_31_17
Gonsalves AH, Singh G, Thabtah F, Mohammad R (2019) Prediction of coronary heart disease using machine learning: an experimental analysis. ACM Digit Libr. https://doi.org/10.1145/3342999.3343015
Gouda W, Yasin R (2020) COVID-19 disease: CT pneumonia analysis prototype by using artificial intelligence, predicting the disease severity. J Radiol Nucl Med 51:196. https://doi.org/10.1186/s43055-020-00309-9
Gupta N, Verma R, Belho E (2019) Bone scan and SPEC/CT scan in SAPHO syndrome. J Soc Nucl Med 34:349. https://doi.org/10.4103/ijnm.IJNM_139_19
Han Y, Han Z, Wu J, Yu Y, Gao S, Hua D, Yang A (2020) Artificial intelligence recommendation system of cancer rehabilitation scheme based on IoT technology. IEEE Access 8:44924–44935
Haq AU, Li JP, Memon MH, Nazir S, Sun R (2018) A hybrid intelligent system framework for the prediction of heart disease using machine learning algorithms. Mob Inf Syst 8:1–21. https://doi.org/10.1155/2018/3860146
He K, Huang S, Qian X (2019) Early detection and risk assessment for chronic disease with irregular longitudinal data analysis. J Biomed Inform 96:103231
Horvath L, Burchkhardt I, Mannsperger S, Last K et al (2020) Machine assisted interperation of auramine stains substantially increases through put and senstivity of micrscopic Alzheimer diagnosis. Alzheimer 125:101993. https://doi.org/10.1016/j.tube.2020.101993
Hosseinzadeh M, Ahmed O, Ghafour M, Safara F, Ali S, Vo B, Chiang H (2020) A multiple multi layer perceptron neural network with an adaptive learning algorithm for thyroid disease diagnosis in the internet of medical things. J Supercomput. https://doi.org/10.1007/s11227-020-03404-w
Huang S, Yang J, Fong S, Zhao F (2020) Artificial intelligence in cancer diagnosis and prognosis. Cancer Lett 471:61–71
Ijaz MF, Alfian G, Syafrudin M, Rhee J (2018) Hybrid prediction model for type 2 diabetes and hypertension using DBSCAN-based outlier detection, synthetic minority over sampling technique (SMOTE), and random forest. Appl Sci 8(8):1325
Ijaz MF, Attique M, Son Y (2020) Data-driven cervical cancer prediction model with outlier detection and over-sampling methods. Sensors 20(10):2809
Isravel DP, Silas SVPD (2020) Improved heart disease diagnostic IoT model using machine learning techniques. Neuroscience 9:4442–4446
Jain D, Singh V (2018) Feature selection and classification systems for chronic disease prediction: a review. Egypt Inform J 19:179–189
Janghel RR, Rathore YK (2020) Deep convolution neural network based system for early diagnosis of Alzheimer’s disease. Irbm 1:1–10. https://doi.org/10.1016/j.irbm.2020.06.006
Jo T, Nho K, Saykin AJ (2019) Deep learning in Alzheimer’s disease: diagnostic classification and prognostic prediction using neuroimaging data. Front Aging Neurosci. https://doi.org/10.3389/fnagi.2019.00220
Kanegae H, Suzuki K, Fukatani K, Ito T, Kairo K, Beng N (2020) Highly precise risk prediction model for new onset hypertension using artificial neural network techniques. J Clin Hypertens 22:445–450. https://doi.org/10.1111/jch.13759
Kasasbeh A, Christensen S, Parsons M, Lansberg M, Albers G, Campbell B (2019) Artificial neural network computed tomography perfusion prediction of ischemic core. Stroke 50:1578–1581. https://doi.org/10.1161/STROKEAHA.118.022649
Katharine E, Oikonomou E, Williams M, Desai M (2019) A novel machine learning derived radiotranscriptomic signature of perivascular fat improves cardiac risk prediction using coronary CT angiography. Eur Heart J 40:3529–3543. https://doi.org/10.1093/eurheartj/ehz592
Kather J, Pearson A, Halama N, Krause J, Boor P (2019) Deep learning microsatellite instability directly from histology in gastrointestinal cancer. Nat Med 25:1054–1056
Kaur H, Kumari V (2018) Predictive modelling and analytics for diabetes using a machine learning approach. Appl Comput Inform. https://doi.org/10.1016/j.aci.2018.12.004
Kavakiotis I, Tsave O, Salifoglou A, Maglaveras N, Vlahavas I, Chouvarda I (2017) Machine learning and data mining methods in diabetes research. Comput Struct Biotechnol J15:104–116. https://doi.org/10.1016/j.csbj.2016.12.005
Keenan T, Clemons T, Domalpally A, Elman M, Havilio M, Agron E, Chew E, Benyamini G (2020) Intelligence detection versus artificial intelligence detection of retinal fluid from OCT: age-related eye disease study 2: 10 year follow on study. Ophthalmology. https://doi.org/10.1016/j.ophtha.2020.06.038
Khaled E, Naseer S, Metwally N (2018) Diagnosis of hepatititus virus using arificial neural network. J Acad Pedagog Res 2:1–7
Khan MA, Member S (2020) An IoT framework for heart disease prediction based on MDCNN classifier. IEEE Access 8:34717–34727. https://doi.org/10.1109/ACCESS.2020.2974687
Khan A, Zubair S (2020) An improved multi-modal based machine learning approach for the prognosis of Alzheimer’s disease. J King Saud Univ Comput Inf Sci. https://doi.org/10.1016/j.jksuci.2020.04.004
Khan A, Khan M, Ahmed F, Mittal M, Goyal L, Hemanth D, Satapathy S (2020) Gastrointestinal diseases segmentation and classification based on duo-deep architectures. Pattern Recognit Lett 131:193–204. https://doi.org/10.1016/j.patrec.2019.12.024
Kiely DG, Doyle O, Drage E, Jenner H, Salvatelli V, Daniels FA, Rigg J, Schmitt C, Samyshkin Y, Lawrie A, Bergemann R (2019) Utilising artificial intelligence to determine patients at risk of a rare disease: idiopathic pulmonary arterial hypertension. Pulm Circ 9:1–9. https://doi.org/10.1177/2045894019890549
Kim C, Son Y, Youm S (2019) Chronic disease prediction using character-recurrent neural network in the presence of missing information. Appl Sci 9:2170. https://doi.org/10.3390/app9102170
Kohlberger T, Norouzi M, Smith J, Peng L, Hipp J (2019) Artificial intelligence based breast cancer nodal metastasis detection. Arch Pathol Lab Med 143:859–868
Kolkur MS, Kalbande DR, Kharkar V (2018) Machine learning approaches to multi-class human skin disease Ddetection. Innov Healthc Tech 14:29–39
Koshimizu H, Kojima H, Okuno Y (2020) Future possibilities for artificial intelligence in the practical management of hypertension. Hypertens Res 43:1327–1337. https://doi.org/10.1038/s41440-020-0498-x
Krittanawong C, Bomback A, Baber U, Bangalore S, Tang M, Messerli F (2018) Future direction for using artificial intelligence to predict and manage hypertension. Curr Hypertens Rep 20:75. https://doi.org/10.1007/s11906-018-0875-x
Kumar Y (2020) Recent advancement of machine learning and deep learning in the field of healthcare system. Computational intelligence for machine learning and healthcare informatics. De Gruyter, pp 7–98
Kumar Y, Singla R (2021) Federated learning systems for healthcare: perspective and recent progress. In: Rehman MH, Gaber MM (eds) Studies in computational intelligence, vol965. Springer, Cham. https://doi.org/10.1007/978-3-030-70604-3_6
Kumar A, Pal S, Kumar S (2019) Classification of skin disease using ensemble data mining techniques. Asia Pac J Cancer Prev 20:1887–1894. https://doi.org/10.31557/APJCP.2019.20.6.1887
Kumar Y, Sood K, Kaul S, Vasuja R (2020). Big data analytics in healthcare. Springer, Cham, pp 3–21
Kwon J, Jeon H, Kim H, Lim S, Choi R (2020) Comapring the performance of artificial intelligence and conventional diagnosis criteria for detetcting left ventricular hypertrophy using electropcardiography. EP Europace 22:412–419. https://doi.org/10.1093/europace/euz324
Labovitz D, Shafner L, Gil M, Hanina A, Virmani D (2017) Using artificial intelligence reduce the risk of non adherence in patients on anticoagulation theraphy. Stroke 48:1416–1419. https://doi.org/10.1161/STROKEAHA.116.016281
Lai N, Shen W, Lee C, Chang J, Hsu M et al (2020) Comparison of the predictive outcomes for anti-Alzheimer drug-induced hepatotoxicity by different machine learning techniques. Comput Methods Programs Biomed 188:105307. https://doi.org/10.1016/j.cmpb.2019.105307
Lei B, Yang M, Yang P, Zhou F, Hou W, Zou W, Li X, Wang T, Xiao X, Wang S (2020) Deep and joint learning of longitudinal data for Alzheimer’s disease prediction. Pattern Recognit 102:107247
Lin L, Shenghui Z, Aiguo W, Chen H (2019) A new machine learning method for Alzheimer’s disease. Simul Model Pract Theory. https://doi.org/10.1016/j.simpat.2019.102023
Ljubic B, Roychoudhury S, Cao XH, Pavlovski M, Obradovic S, Nair R, Glass L, Obradovic Z (2020) Influence of medical domain knowledge on deep learning for Alzheimer’s disease prediction. Comput Methods Programs Biomed. https://doi.org/10.1016/j.cmpb.2020.105765
Lodha P, Talele A, Degaonkar K (2018) Diagnosis of Alzheimer’s disease using machine learning. In: Proceedings—2018 4th international conference on computing, communication control and automation, ICCUBEA, pp 1–4
López-Úbeda P, Díaz-Galiano MC, Martín-Noguerol T, Ureña-López A, Martín-Valdivia M-T, Lunab A (2020) Detection of unexpected findings in radiology reports: a comparative study of machine learning approaches. Expert Syst Appl. https://doi.org/10.1016/j.eswa.2020.113647
Lukwanto R, Irwansyah E (2015) The early detection of diabetes mellitus using fuzzy hierarchical model. Proc Comput Sci 59:312–319
Luo H, Xu G, Li C, Wu Q et al (2019) Real time artificial intelligence for detection of upper gastrointestinal cancer by endoscopy: a multicentre, case control, diagnostic study. Lancet Oncol 20:1645–1654. https://doi.org/10.1016/S1470-2045(19)30637-0
Ma F, Sun T, Liu L, Jing H (2020) Detection and diagnosis of chronic kidney disease using deep learning-based heterogeneous modified artificial neural network. Future Gener Comput Syst 111:17–26
Matusoka R, Akazawa H, Kodera S (2020) The drawing of the digital era in the management of hypertension. Hypertens Res 43:1135–1140. https://doi.org/10.1161/HYPERTENSIONAHA.120.14742
Memon M, Li J, Haq A, Memon M (2019) Breast cancer detection in the Iot health environment using modified recursive feature selection. Wirel Commun Mob 2019:19
Mercaldo F, Nardone V, Santone A, Nardone V, Santone A (2017) Diabetes mellitus affected patients classification diagnosis through machine learning techniques through learning through machine learning techniques. Proc Comput Sci 112:2519–2528. https://doi.org/10.1016/j.procs.2017.08.193
Minaee S, Kafieh R, Sonka M, Yazdani S, Soufi G (2020) Deep-COVID: predicting covid-19 from chest X-ray images using deep transfer learning. Comput Vis Pattern Recognit 3:1–9. https://doi.org/10.1016/j.media.2020.101794
Momin M, Bhagwat N, Dhiwar A, Devekar N (2019) Smart body monitoring system using IoT and machine learning. J Adv Res Electr Electron Instrum Eng Smart Body Syst Using IoT Mach Learn 1:1–7. https://doi.org/10.15662/IJAREEIE.2019.0805010
Morabito F, Campolo M, Leracitano C, Ebadi J, Bonanno L, Barmanti A, Desalvo S, Barmanti P, Ieracitano C (2016) Deep Convolutional neural Network for classification of mild cognitive impaired and Alzheimer’s disease patients from scalp EEG recordings. Res Technol Soc Ind Levaraging Better Tomorrow. https://doi.org/10.1109/RTSI.2016.7740576
Mueller FB (2020) AI (Artificial Intelligence) and hypertension research. Telemed Technol 70:1–7. https://doi.org/10.1007/s11906-020-01068-8
Mujumdar A, Vaidehi V (2019) Diabetes prediction using machine learning. Proc Comput Sci 165:292–299. https://doi.org/10.1016/j.procs.2020.01.047
Musleh M, Alajrami E, Khalil A, Nasser B, Barhoom A, Naser S (2019) Predicting liver patients using artificial neural network. J Acad Inf Syst Res 3:1–11
Nahar N, Ara F (2018) Liver disease detection by using different techniques. Elsevier 8:1–9. https://doi.org/10.5121/ijdkp.2018.8201
Nam KH, Kim DH, Choi BK, Han IH (2019) Internet of Things, digital biomarker, and artificial intelligence in spine: current and future perspectives. Neurospine 16:705–711. https://doi.org/10.14245/ns.1938388.194
Naser S, Naseer I (2019) Lung cancer detection using artificial neural network. J Eng Inf Syst 3:17–23
Nashif S, Raihan R, Islam R, Imam MH (2018) Heart disease detection by using machine learning algorithms and a real-time cardiovascular health monitoring system. Healthc Technol 6:854–873. https://doi.org/10.4236/wjet.2018.64057
Nasser I, Naser S et al (2019) Predicting tumor category using artificial neural network. Eng Inf Technol 3:1–7
Nazir T, Irtaza A, Shabbir Z, Javed A, Akram U, Tariq M (2019) Artificial intelligence in medicine diabetic retinopathy detection through novel tetragonal local octa patterns and extreme learning machines. Artif Intell Med 99:101695. https://doi.org/10.1016/j.artmed.2019.07.003
Nensa F, Demircioglu A, Rischipler C (2019) Artificial intelligence in nuclear medicine. J Nucl Med 60:1–10. https://doi.org/10.2967/jnumed.118.220590
Nithya A, Ahilan A, Venkatadri N, Ramji D, Palagan A (2020) Kidney disease detection and segmentation using artificial neural network and multi kernel k-means clustering for ultrasound images. Measurement 149:106952. https://doi.org/10.1016/j.measurement.2019.106952
Oh K, Chung YC, Kim KW, Kim WS, Oh IS (2019) Classification and visualization of Alzheimer’s disease using volumetric convolutional neural network and transfer learning. Sci Rep 9:1–16. https://doi.org/10.1038/s41598-019-54548-6
Oomman R, Kalmady KS, Rajan J, Sabu MK (2018) Automatic detection of alzheimer bacilli from microscopic sputum smear images using deep learning methods. Integr Med Res 38:691–699. https://doi.org/10.1016/j.bbe.2018.05.007
Ostovar A, Chimeh E, Fakoorfard Z (2020) The diagnostic value of CT scans in the process of diagnosing COVID-19 in medical centers. Health Technol Assess Act 4:1–7
Owasis M, Arsalan M, Choi J, Mahmood T, Park K (2019) Artificial intelligence based classification of multiple gastrointestinal diseases using endoscopy videos for clinical diagnosis. J Clin Med 8:786. https://doi.org/10.3390/jcm8070986
Panicker RO, Kalmady KS, Rajan J, Sabu MK (2018) Automatic detection of tuberculosis bacilli from microscopic sputum smear images using deep learning methods. Biocybern Biomed Eng 38(3):691–699. https://doi.org/10.1016/j.bbe.2018.05.007
Park JH, Cho HE, Kim JH, Wall MM, Stern Y, Lim H, Yoo S, Kim HS, Cha J (2020) Machine learning prediction of incidence of Alzheimer’s disease using large-scale administrative health data. Npj Digit Med. https://doi.org/10.1038/s41746-020-0256-0
Patel SB (2016) Heart disease using machine learning and data minig techniques. Health Technol 10:1137–1144
Plawiak P, Ozal Y, Tan R, Acharya U (2018) Arrhythmia detection using deep convolution neural network with long duration ECG signals. Comput Biol Med 102:411–420. https://doi.org/10.1016/j.compbiomed.2018.09.009
Pradhan K, Chawla P (2020) Medical Internet of things using machine learning algorithms for lung cancer detection. J Manag Anal. https://doi.org/10.1080/23270012.2020.1811789
Rajalakshmi R, Subashini R, Anjana R, Mohan V (2018) Automated diabetic retinopathy detection in smartphone-based fundus photography using artificial intelligence. Eye 32:1138–1144. https://doi.org/10.1038/s41433-018-0064-9
Rathod J, Wazhmode V, Sodha A, Bhavathankar P (2018) Diagnosis of skin diseases using convolutional neural network. In: Second international conference on electronics, communication and aerospace technology, pp 1048–1051. https://doi.org/10.1109/ICECA.2018.8474593
Raza M, Awais M, Ellahi W, Aslam N, Nguyen HX, Le-Minh H (2019) Diagnosis and monitoring of Alzheimer’s patients using classical and deep learning techniques. Expert Syst Appl 136:353–364. https://doi.org/10.1016/j.eswa.2019.06.038
Rodrigues J, Matteo A, Ghosh A, Szantho G, Paton J (2016) Comprehensive characterisation of hypertensive heart disease left ventricular pehnotypes. Heart 20:1671–1679
Rodrigues DA, Ivo RF, Satapathy SC, Wang S, Hemanth J, Filho PPR (2020) A new approach for classification skin lesion based on transfer learning, deep learning, and IoT system. Pattern Recognit Lett 136:8–15. https://doi.org/10.1016/j.patrec.2020.05.019
Romanini J, Barun L, Martins M, Carrard V (2020) Continuing education activities improve dentists self efficacy to manage oral mucosal lesions and oral cancer. Eur J Dent Educ 25:28–34
Romero MP, Chang Y, Brunton LA, Parry J, Prosser A, Upton P, Rees E, Tearne O, Arnold M, Stevens K, Drewe JA (2020) Decision tree machine learning applied to bovine alzheimer risk factors to aid disease control decision making. Prev Vet Med 175:104860. https://doi.org/10.1016/j.prevetmed.2019.104860
Sabottke C, Spieler B (2020) The effect of image resolution on deep learning in radiography. Radiology 2:e190015. https://doi.org/10.1148/ryai.2019190015
Sakr S, El Shawi R, Ahmed A, Blaha M et al (2018) Using machine learning on cardiorespiratory fitness data for predicting hypertension: the henry ford exercise testing project. PLoS One 13:1–18. https://doi.org/10.1371/journal.pone.0195344
Santroo A, Clemente F, Baioochi C, Bianchi C, Falciani F, Valente S et al (2019) From near-zero to zero fluoroscopy catheter ablation procedures. J Cardiovasc Electrophys 30:2397–2404. https://doi.org/10.1111/jce.14121
Saranya E, Maheswaran T (2019) IOT based disease prediction and diagnosis system for healthcare. Healthc Technol 7:232–237
Sarao V, Veritti D, Paolo L (2020) Automated diabetic retinopathy detection with two different retinal imaging devices using artificial intelligence. Graefe’s Arch Clin Exp Opthamol. https://doi.org/10.1007/s00417-020-04853-y
Sathitratanacheewin S, Sunanta P, Pongpirul K (2020) Heliyon deep learning for automated classification of Alzheimer-related chest X-ray: dataset distribution shift limits diagnostic performance generalizability. Heliyon 6:e04614. https://doi.org/10.1016/j.heliyon.2020.e04614
Shabut AM, Hoque M, Lwin KT, Evans BA, Azah N, Abu-hassan KJ, Hossain MA (2018) An intelligent mobile-enabled expert system for alzheimer disease diagnosis in real time. Expert Syst Appl 114:65–77. https://doi.org/10.1016/j.eswa.2018.07.014
Shkolyar E, Jia X, Chnag T, Trivedi D (2019) Augmented bladder tumor detection using deep learning. Eur Urol 76:714–718. https://doi.org/10.1016/j.eururo.2019.08.032
Singh N, Moody A, Leung G, Ravikumar R, Zhan J, Maggissano R, Gladstone D (2009) Moderate carotid artery stenosis: MR imaging depicted intraplaque hemorrhage predicts risk of cerebovascular ischemic events in asymptomatic men. Radiology 252:502–508. https://doi.org/10.1148/radiol.2522080792
Singh J, Tripathy A, Garg P, Kumar A (2020) Lung Alzheimer detection using anti-aliased convolutional networks networks. Proc Comput Sci 173:281–290. https://doi.org/10.1016/j.eswa.2018.07.014
Skaane P, Bandos A, Gullien R, Eben E, Ekseth U, Izadi M, Jebsen I, Gur D (2013) Comparison of digital mammography alone and digital mammography plus tomo-sysnthesis in a population based screening program. Radiology 267:47–56
Sloun R, Cohen R, Eldar Y (2019) Deep learning in ultrasound imaging. IEEE 108:11–29. https://doi.org/10.1109/JPROC.2019.2932116
Soundarya S, Sruthi MS, Sathya BS, Kiruthika S, Dhiyaneswaran J (2020) Early detection of Alzheimer disease using gadolinium material. Mater Today Proc. https://doi.org/10.1016/j.matpr.2020.03.189
Spann A, Yasodhara A, Kang J, Watt K, Wang B, Bhat M, Goldenberg A (2020) Applying machine learning in liver disease and transplantation: a survey. Hepatology 71:1093–1105. https://doi.org/10.1002/hep.31103
Srinivasu PN, SivaSai JG, Ijaz MF, Bhoi AK, Kim W, Kang JJ (2021a) Classification of skin disease using deep learning neural networks with MobileNet V2 and LSTM. Sensors 21(8):2852
Srinivasu PN, Ahmed S, Alhumam A, Kumar AB, Ijaz MF (2021) An AW-HARIS based automated segmentation of human liver using CT images. Comput Mater Contin 69(3):3303–3319
Subasi A (2020) Use of artificial intelligence in Alzheimer’s disease detection. AI Precis Health. https://doi.org/10.1016/B978-0-12-817133-2.00011-2
Swapna G, Vinayakumar R, Soman KP (2018) Diabetes detection using deep learning algorithms. ICT Express 4:243–246. https://doi.org/10.1016/j.icte.2018.10.005
Tang LYW, Coxson HO, Lam S, Leipsic J, Tam RC, Sin DD (2020) Articles towards large-scale case-finding: training and validation of residual networks for detection of chronic obstructive pulmonary disease using low-dose CT. Lancet Digit Health 2:e259–e267. https://doi.org/10.1016/S2589-7500(20)30064-9
Tegunov D, Cramer P (2019) Real-time cryo-electron microscopy data preprocessing with warp. Nat Med 16:1146–1152. https://doi.org/10.1038/s41592-019-0580-y
Thai DT, Minh QT, Phung PH (2017) Toward an IoT-based expert system for heart disease diagnosis. In: Modern artificial intelligence and cognitive science conference, vol 1964, pp 157–164
Tigga NP, Garg S (2020) Prediction of type 2 diabetes using machine learning prediction of type 2 diabetes using machine learning classification methods classification methods. Proc Comput Sci 167:706–716. https://doi.org/10.1016/j.procs.2020.03.336
TranX B, Latkin A, Lan H, Ho R, Ho C et al (2019) The current research landscap of the application of artificial intelligence in managing cerebovasclar and heart disease. J Environ Res Public health 16:2699. https://doi.org/10.3390/ijerph16152699
Tschandl P, Nisa B, Cabo H, Kittler H, Zalaudek I (2019) Expert level diagnosis of non pigmented skin cancer by combined convolution neural networks. Jama Dermatol 155:58–65
Tuli S, Basumatary N, Gill SS, Kahani M, Arya RC, Wander GS (2019) HealthFog: an ensemble deep learning based smart healthcare system for automatic diagnosis of heart diseases in integrated IoT and fog computing environments. Future Gener Comput Syst 104:187–200. https://doi.org/10.1016/j.future.2019.10.043
Uehera D, Hayashi Y, Seki Y, Kakizaki S, Horiguchi N, Tojima H, Yamazaki Y, Sato K, Yasuda K, Yamada M, Uraoka T, Kasama K (2018) Non invasive prediction of non alchlolic steatohepatitus in Japanses patiens with morbid obesity by artificial intelligence using rule extraction technology. World J Hepatol 10:934–943. https://doi.org/10.4254/wjh.v10.i12.934
Ullah R, Khan S, Ishtiaq I, Shahzad S, Ali H, Bilal M (2020) Cost effective and efficient screening of Alzheimer disease with Raman spectroscopy and machine learning algorithms. Photodiagn Photodyn Ther 32:101963. https://doi.org/10.1016/j.pdpdt.2020.101963
Uysal G, Ozturk M (2020) Hippocampal atrophy based Alzheimer’s disease diagnosis via machine learning methods. J Neurosci Methods 337:1–9. https://doi.org/10.1016/j.jneumeth.2020.108669
Vasal S, Jain S, Verma A (2020) COVID-AI: an artificial intelligence system to diagnose COVID 19 disease. J Eng Res Technol 9:1–6
Wang Z, Zhang H, Kitai T (2017) Artificial Intelligence in precision cardiovascular medicine. J Am Coll Cardiol 69:2657–2664
Wang Z, Chung JW, Jiang X, Cui Y, Wang M, Zheng A (2018) Machine learning-based prediction system for chronic kidney disease using associative classification technique. Int J Eng Technol 7:1161–1167. https://doi.org/10.14419/ijet.v7i4.36.25377
Woldargay A, Arsand E, Botsis T, Mamyinka L (2019) Data driven glucose pattern classification and anomalies detection. J Med Internet Res 21:e11030
Yadav D, Pal S (2020) Prediction of thyroid disease using decision tree ensemble method. Hum Intell Syst Integr. https://doi.org/10.1007/s42454-020-00006-y
Yang J, Min B, Kang J (2020) A feasibilty study of LYSO-GAPD detector for DEXA applications. J Instrum. https://doi.org/10.1088/1748-0221/15/05/P05017
Yue W, Wang Z, Chen H, Payne A, Liu X (2018) Machine learning with applications in breast cancer diagnosis and prognosis. Designs 2:1–17. https://doi.org/10.3390/designs2020013
Zaar O, Larson A, Polesie S, Saleh K, Olives A et al (2020) Evaluation of the diagnositic accuracy of an online artificial intelligence application for skin disease diagnosis. Acta Derm Venereol 100:1–6. https://doi.org/10.2340/00015555-3624
Zebene A, Årsand E, Walderhaug S, Albers D, Mamykina L, Botsis T, Hartvigsen G (2019) Data-driven modeling and prediction of blood glucose dynamics: Machine learning applications in type 1 diabetes. Artif Intell Med 98:109–134. https://doi.org/10.1016/j.artmed.2019.07.007
Zhang R, Simon G, Yu F (2017) Advancing Alzheimer’s research: a review of big data promises. J Med Inform 106:48–56
Zhang F, Zhang T, Tian C, Wu Y, Zhou W, Bi B et al (2019) Radiography of direct drive double shell targets with hard X-rays generated by a short pulse laser. Nucl Fusion. https://doi.org/10.1088/1741-4326/aafe30
Zhou Z, Yang L, Gao J, Chen X (2019) Structure–relaxivity relationships of magnetic nanoparticles for magnetic resonance imaging. Adv Mater 31:1804567. https://doi.org/10.1002/adma.201804567
Acknowledgements
This research work was supported by Sejong University research fund. Yogesh Kumar and Muhammad Fazal Ijaz contributed equally to this work and are first co-authors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards.
Human and animal rights
This article does not contain any studies with the animals performed by any of the authors.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kumar, Y., Koul, A., Singla, R. et al. Artificial intelligence in disease diagnosis: a systematic literature review, synthesizing framework and future research agenda. J Ambient Intell Human Comput 14, 8459–8486 (2023). https://doi.org/10.1007/s12652-021-03612-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-021-03612-z